
Your AI model is only as reliable as the data that trained it.
Most marketplace AI teams know this in principle. Few have built the quality infrastructure to act on it. The result is a pattern that repeats across e-commerce platforms at scale: a model that performs well on benchmarks but degrades in production — showing users the wrong products, ranking irrelevant results, and making category errors that compound quietly over time.
The fix is not a better model. It is a better control layer. And that control layer is Human-in-the-Loop (HITL) quality.
What Is HITL Quality – and Why Does It Matter for Marketplace AI?
Human-in-the-loop quality is the systematic process of embedding human judgment into AI pipelines — not as a final check, but as a continuous feedback mechanism that validates, corrects, and improves model outputs at every stage.
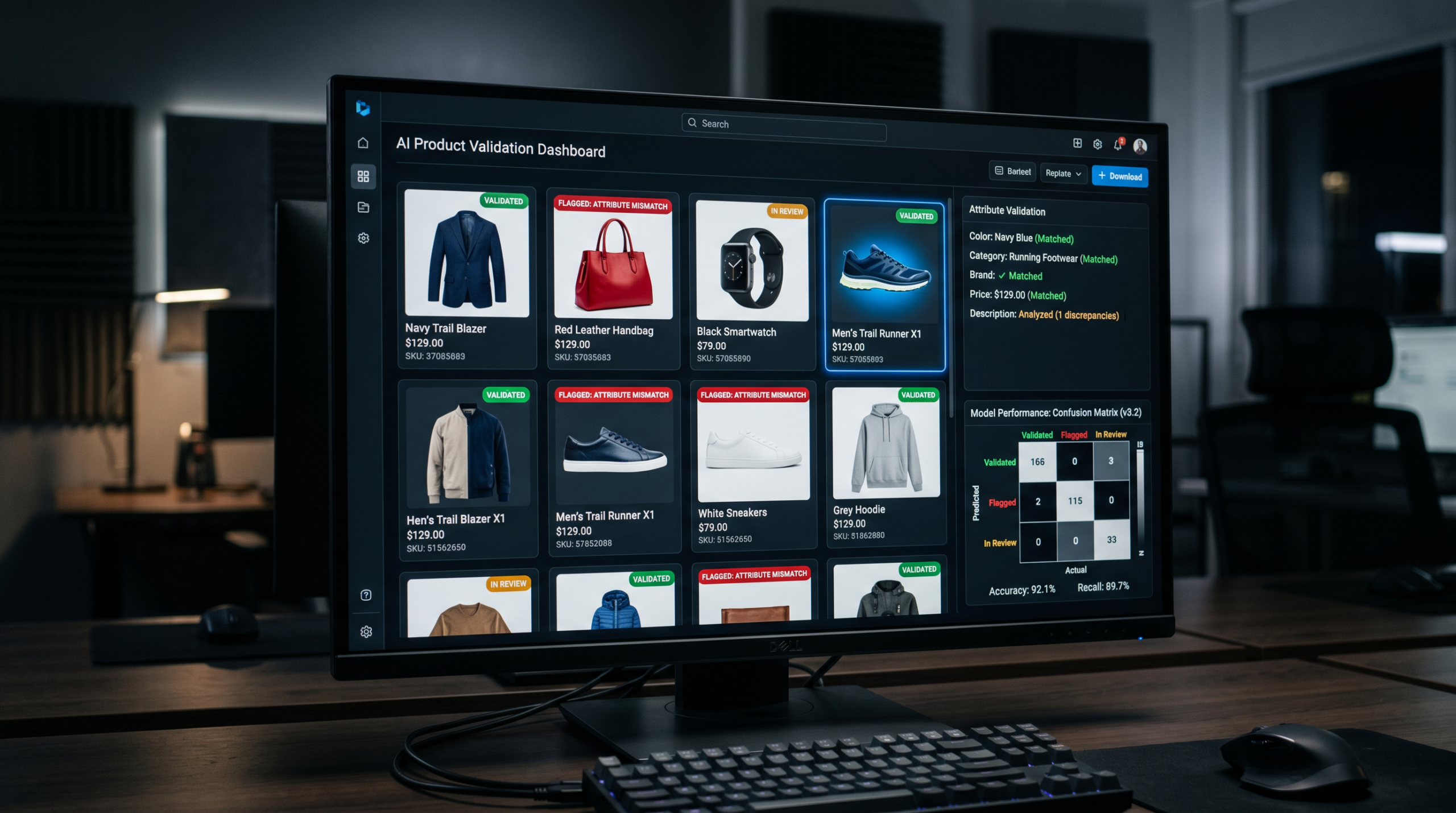
In a marketplace context, this means humans reviewing and correcting the outputs that AI systems generate across catalog tasks: product categorization, attribute annotation, image validation, relevance labeling, content enrichment, and compliance tagging.
Each of these tasks produces a different kind of supervision signal. And each signal, when it is wrong, breaks the AI system in a different way.
This is the core insight that most quality programs miss: HITL is not a single workflow. It is a task-specific control layer — and the metrics that matter change depending on what is being validated.
The Metric That Is Quietly Breaking Your AI
Here is the most common mistake in marketplace AI quality programs: optimising for accuracy and stopping there.
Accuracy measures overall correctness. If 95 out of 100 annotations are correct, accuracy is 95%. That sounds strong. But if the 5 errors are all in the same high-stakes category — a restricted product approved, a brand misclassified, a relevant product pushed out of search results — then 95% accuracy is masking a serious production failure.
The confusion matrix tells a more complete story. Every annotation falls into one of four outcomes: True Positive, False Positive, False Negative, or True Negative. The distribution across these four outcomes reveals the actual error structure — and error structure determines downstream model behavior.
Precision measures how many predicted positives are actually correct. Low precision means your AI is introducing noise — showing users products that don’t belong, contaminating category clusters, distorting the feature space models learn from.
Recall measures how many actual positives were captured. Low recall means your AI is missing things — relevant products excluded from search, violations slipping through compliance, attributes left blank in product records.
F1 Score balances the two. Cohen’s Kappa measures whether your human reviewers are actually agreeing with each other — or introducing contradictory labels that teach your model conflicting things.
A high-quality HITL program tracks all of these. Not just accuracy.
Where Catalog AI Breaks — And What the Data Shows
Product Categorization: When Precision Collapses
A large marketplace saw users searching for running shoes being shown casual sneakers. Category accuracy looked acceptable at the top level. But precision within subcategories — Running Shoes, Training Shoes, Walking Shoes — had fallen to 88–90%.
False positives were contaminating category clusters. The model learned that visually different products belonged together. Embedding clusters that should have been separated began to overlap.
After stricter category validation with HITL review, precision rose above 95%. The result: an 11% improvement in click-through rate on affected footwear queries. Category purity is a precision problem — and precision is the metric that protects it.
Attribute Annotation: When a Single Field Corrupts Everything
An electronics marketplace found users applying the 16GB RAM filter were seeing 8GB products. The issue was not the search engine. It was attribute annotation — reviewers were extracting RAM values from promotional text rather than verified product specifications.
Attribute accuracy showed 94% overall. But targeted at RAM specifically, precision was only 89%. One corrupted attribute field, at scale, broke the entire filter experience.
After validation rules and completeness checks, RAM precision rose above 96% and filtered search bounce rate fell by 18%.
Relevance Labeling: When Recall Collapses Search
A marketplace running broad discovery queries — “running shoes”, “office chair”, “wireless headphones” — saw declining click-through. Offline accuracy looked healthy at 93%. The real problem was recall at only 78% for borderline-relevant products.
Annotators were consistently missing items that were relevant but not exact lexical matches. The model learned a narrow interpretation of relevance, pushed useful products away from query vectors, and results became repetitive.
After shifting to graded relevance labels and monitoring Precision@10 and nDCG alongside classification metrics: CTR increased 14%, conversion improved 8%.
Compliance Tagging: When Accuracy Is Dangerously Misleading
A regulated marketplace reported 95%+ compliance tagging accuracy. Policy escalations continued. A deeper audit revealed a 12% false negative rate on restricted products — violations the model was missing entirely because they used indirect language or implied restricted use through images rather than explicit terms.
After shifting optimisation to recall and Critical Error Rate, severe misses decreased by 70%. In compliance, accuracy is not the controlling metric. Recall is — because a missed violation carries legal and trust consequences that no overall accuracy figure can mask.
The Right Metric for Each HITL Task
| Task | Primary metric | Why |
|---|---|---|
| Product categorization | Precision | False positives contaminate class boundaries |
| Attribute annotation | Precision + Recall | Both corrupt features and reduce discoverability |
| Image validation | Recall | Missed mismatches corrupt multimodal embeddings |
| Relevance labeling | Recall + F1 + nDCG | Coverage and ranking geometry both matter |
| Compliance tagging | Recall + Critical Error Rate | Missed violations dominate the risk profile |
| Content moderation | Cohen’s Kappa | Inconsistent labels create contradictory training signals |
| Content enrichment | Precision | Over-enrichment creates hallucinated attributes |
HITL Is Not a Cost Centre. It Is a Control Layer.
The teams that treat HITL as a box-ticking exercise — a final QA step before data enters the pipeline — consistently underperform against teams that embed it as a continuous feedback mechanism throughout the AI lifecycle.
The difference is architectural. A closed-loop HITL system feeds validated and corrected outputs back into the model continuously. Every human correction becomes a training signal. Quality compounds over time rather than degrading.
This is what separates marketplace AI that improves with scale from marketplace AI that accumulates errors with scale.
If your quality program is optimising for accuracy and stopping there, you are measuring the wrong thing — and your model is paying the price in production.
NextWealth provides Human-in-the-Loop data quality services for marketplace AI systems — from catalog validation and attribute annotation to relevance labeling and compliance tagging. Talk to our team →
FAQs
What is Human-in-the-Loop (HITL) in marketplace AI?
Human-in-the-loop (HITL) in marketplace AI is the process of embedding human reviewers into AI pipelines to validate, correct, and improve model outputs continuously. In e-commerce, this covers tasks including product categorization, attribute annotation, image validation, relevance labeling, and compliance tagging — each producing different supervision signals that shape how AI systems learn and behave.
Why is accuracy not enough for HITL quality measurement?
Accuracy measures overall correctness but hides the structure of errors. In marketplace AI, a small number of false negatives — a restricted product approved, a relevant result excluded, an attribute incorrectly extracted — can cause significant downstream harm even when overall accuracy appears high. Metrics like precision, recall, F1, Cohen’s Kappa, and Critical Error Rate reveal the specific error types that accuracy masks.
What metrics matter most for catalog quality in AI systems?
The most important metrics depend on the task. Precision matters most for product categorization and content enrichment, where false positives contaminate training data. Recall matters most for image validation, relevance labeling, and compliance tagging, where missed errors remain in the system and cause downstream failures. Cohen’s Kappa is critical for subjective tasks like content moderation, where inconsistent human labels create contradictory training signals.
How does HITL improve marketplace AI search and recommendations?
HITL improves marketplace AI by ensuring that the labels and annotations used to train ranking models, embedding systems, and recommendation engines are accurate, consistent, and complete. Poor relevance labels collapse ranking margins and narrow search results. Poor attribute annotations corrupt filters. Poor category labels distort embedding clusters. HITL catches and corrects these errors before they enter the model — and feeds corrections back continuously to improve performance over time