

Bounding Box Annotation Services
Types of Bounding Box Annotation Services
Our team of expert annotators is adept at various bounding box techniques used to distinguish different elements within the image to be annotated.

Geo Tagging Services
We identify the precise global positioning of your photos, videos, or website, allowing your image to be synchronized with geotagging applications such as Google Earth and Google Maps. Our bounding box annotation solutions enable AI-powered location recognition, making visual search more efficient.
Multi-label Classification Services
We annotate images with multiple labels, allowing objects to be categorized seamlessly. Bounding box image annotation enhances object classification, helping AI differentiate between multiple objects within a single frame.
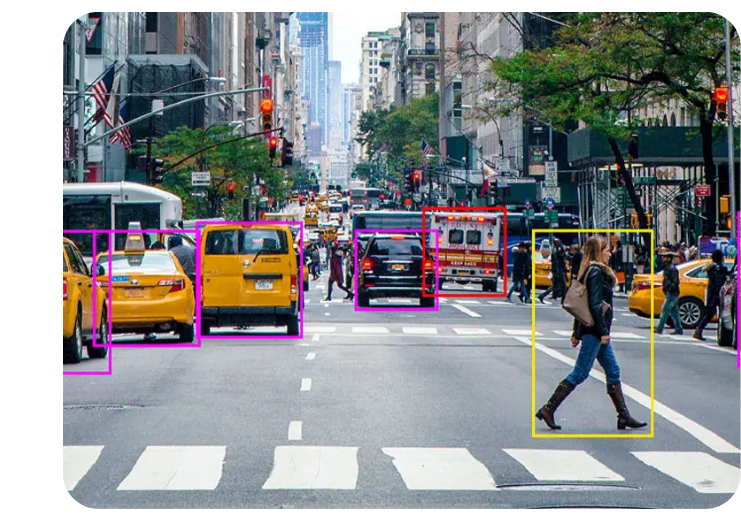

Object Localization Services
Our bounding box annotation technique enables precise object localization, ensuring that AI models can easily detect, track, and segment obstacles within an environment. Our annotation experts guarantee top-quality localization for computer vision applications.
Object Detection Services
We utilize bounding box image annotation by displaying images from multiple angles with accurately labeled datasets. This allows AI models to detect object width, height, shape, and movement with superior precision.
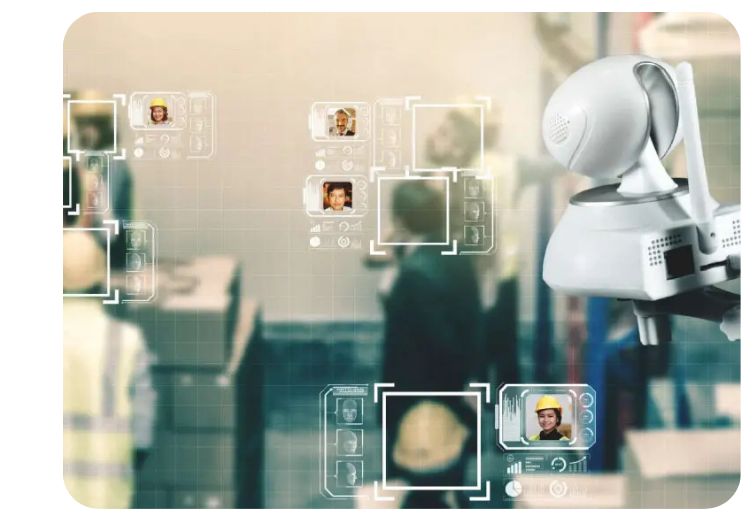
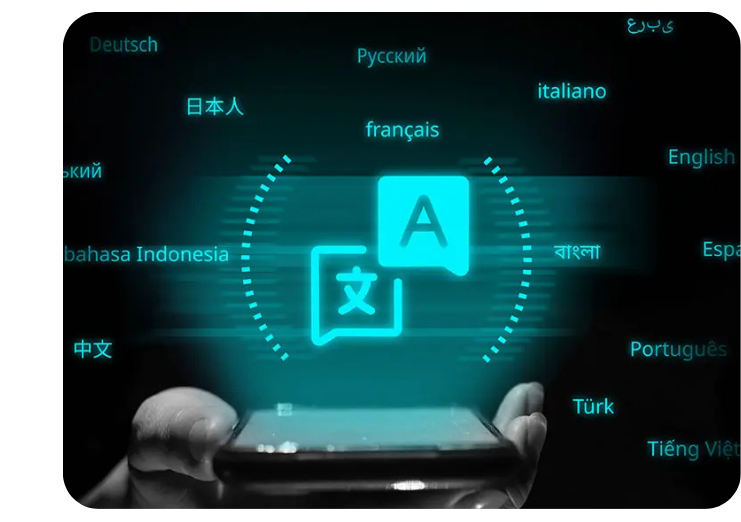
Text Translation Services
We enable image-based text translation through bounding box annotation, making multilingual AI training more seamless. Our annotation experts specialize in training AI models for OCR (Optical Character Recognition) and automated text translation.
Geo Tagging Services

Multi-label Classification Services

Object Localization Services

Object Detection Services

Text Translation Services
Retail & e-Commerce

Bounding box image annotation highlights fashion accessories, clothing, and products for automated tagging and inventory tracking. This makes visual search more effective and streamlines self-checkout systems in retail stores.
Autonomous Vehicles

Autonomous vehicle algorithms rely on bounding box annotation services to detect potholes, traffic signals, lanes, and obstacles. Bounding box image annotation helps self-driving cars recognize their surroundings, improving road safety.
Insurance

Bounding boxes help detect vehicle damage, such as broken windows or dents, during an accident. AI-powered bounding box annotation solutions enable automated damage assessment, streamlining insurance claim processes.
Drone Imagery and Robotics

Bounding box annotation experts enhance drone and robotics AI models by labeling objects from aerial images. Bounding box image annotation improves object recognition, ensuring accurate navigation for drones and robotic applications.
Healthcare

Bounding box annotation in medical imaging aids in tracking anatomical objects such as the heart, tumors, and other features. With accurate bounding box image classification, physicians can leverage AI for precise diagnps 85is and treatment planning.
Agriculture

Bounding box annotation for agriculture allows AI to analyze crop conditions, detect diseases, and optimize farming strategies. AI-powered bounding box annotation services enhance yield prediction and real-time field monitoring.



I am really happy at all the great things we have been able to achieve in the past 1 year. The relationship now has a solid foundation, and I am sure NextWealth will continue to be a formidable partner going ahead, bringing a delightful experience for our customers.
NextWealth has been an invaluable partner to us, significantly accelerating our growth by handling critical data operations and providing strategic insights.
NextWealth’s hard work and dedication are truly making a difference, streamlining our processes significantly. We really appreciate it!
My experience with NextWealth has been wonderful. The diligent team consistently delivers on time with a focus on quality. Their innovation-driven mindset fosters a win-win situation for both teams.
I am happy with the improvement in the performance. I have seen positive improvement, and we have a long way to go.
NextWealth’s in-depth analysis helped us pinpoint exactly what needs to be done to address the issues.
With excellence in Quality, Cost, and TAT—key pillars of any operation—NextWealth sets a benchmark for operational efficiency and beyond.
We have experienced significant growth—a success we could not have achieved without the expert support, hard work, and commitment of NextWealth.

Bridging the Relevance Gap: How AI Data Services Optimize Search and Discovery for Global Marketplaces
2 mins read

Top 10 Indian BPO Companies for Catalog Management & Services
2 mins read
Latest Update




