
Quick Overview
This blog delves into the importance of Reinforcement Learning from Human Feedback (RLHF) and Human-in-the-Loop (HITL) systems in building enterprise-level Large Language Models (LLMs). It outlines how integrating human feedback at scale enhances model accuracy, adaptability, and ethical decision-making. Key topics include:
Key Points:
- The role of RLHF in improving model performance through continuous human feedback.
- How HITL systems ensure that LLMs stay aligned with business goals and ethical standards.
- The benefits of RLHF and HITL for increasing accuracy, reducing errors, and adapting to dynamic business environments.
- Cost-saving advantages of using RLHF and HITL, including faster deployment, reduced retraining costs, and better long-term performance.
- The challenges of scaling RLHF for enterprise LLMs, including resource intensity and consistency in feedback.
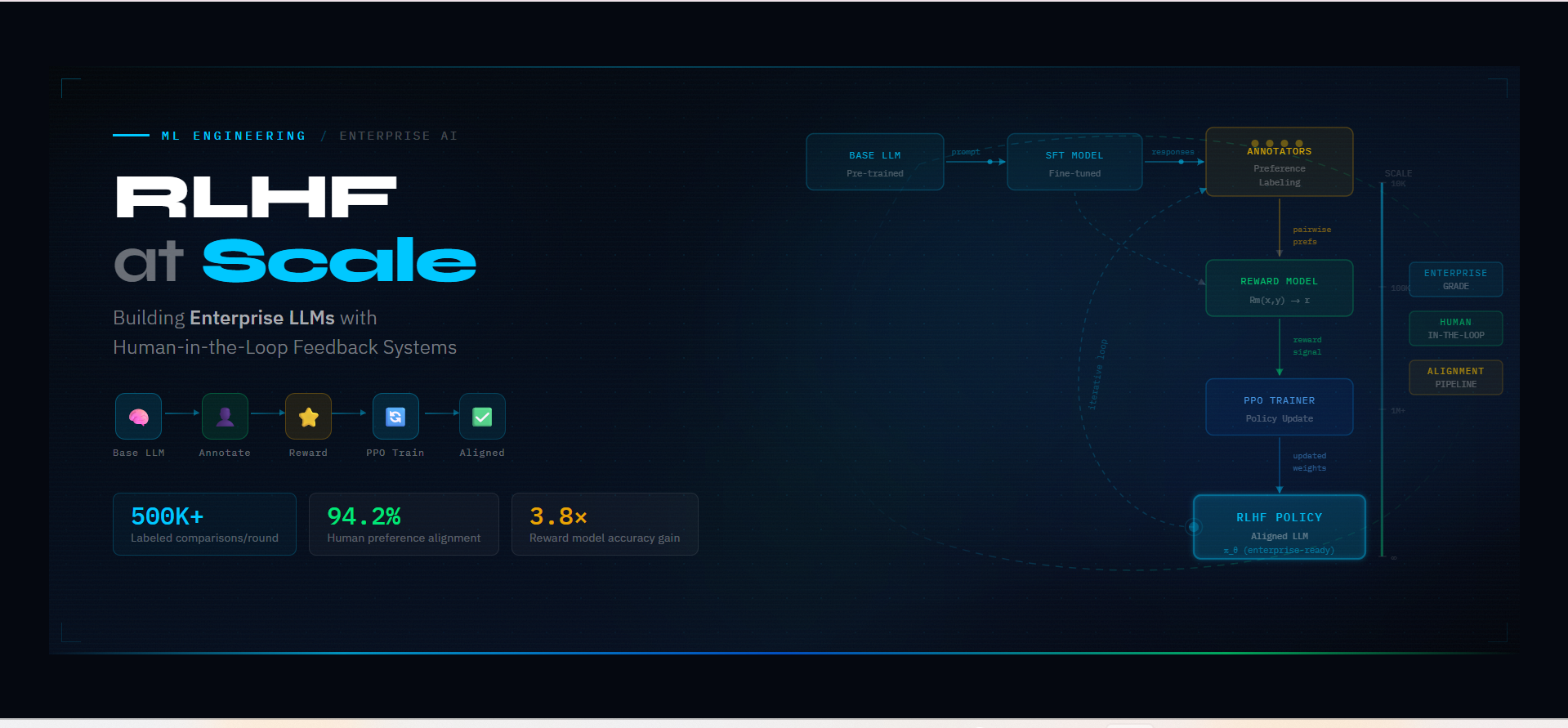
In the world of enterprise-level Large Language Models (LLMs), the challenge is not just about having the capacity to understand and generate human-like text, images, and audio. The real challenge lies in ensuring that these models provide reliable, accurate, and context-sensitive outputs in complex, real-world environments. This is where Reinforcement Learning from Human Feedback (RLHF), combined with Human-in-the-Loop (HITL) systems, plays a pivotal role.
As organizations scale their use of LLMs for diverse applications — from customer service and knowledge management to product recommendations and personalization — incorporating human feedback ensures that these models stay aligned with business goals and human expectations. In this blog, we’ll explore the role of RLHF at scale, how HITL systems make a difference, and why they are crucial in building enterprise-level LLMs.
What is RLHF and How Does It Work in Enterprise LLMs?
Reinforcement Learning from Human Feedback (RLHF) is a training methodology where models learn from human-provided signals to fine-tune their responses or behavior. This is especially important in enterprise settings, where models need to make complex decisions based on context, business priorities, and real-world data.
In RLHF, human evaluators provide feedback based on how well the model’s outputs align with real-world expectations. For example, in a customer support scenario, human feedback ensures that the model’s responses are polite, relevant, and appropriate to the situation. This feedback helps guide the model toward making better decisions, even in scenarios that involve ambiguity or ethical considerations.
Why RLHF and HITL Matter for Building Enterprise LLMs
Enterprise LLMs are designed to process a variety of tasks, from customer queries to product recommendations. The sheer complexity of these tasks demands high-quality, domain-specific outputs, which RLHF and HITL systems help provide by addressing several key challenges:
1. Ensuring Contextual Understanding
Business needs vary across industries, and LLMs must adapt to specific contexts. For example, medical models require understanding of health terminology, while legal models need to interpret contractual language. RLHF, with HITL feedback, allows enterprises to guide models through real-world context so they can accurately interpret complex industry-specific data.
2. Continuous Adaptation and Learning
Markets, customer preferences, and industry trends are always evolving. An enterprise LLM trained only once may become outdated quickly. Through RLHF, human feedback ensures that models evolve continuously, adapting to new data and feedback. This ongoing learning process is key for businesses that want to stay responsive and competitive.
3. Ethical Decision-Making and Bias Correction
Enterprises must ensure that their AI models follow ethical guidelines and avoid amplifying biases. Human evaluators can spot biases in model responses, such as gender or racial biases, and intervene in real time to correct them. RLHF, combined with HITL feedback, ensures that LLMs produce fair and ethically sound outputs.
4. Aligning Outputs with Business Objectives
Business models are designed to meet specific goals, whether it’s enhancing customer support, streamlining internal operations, or increasing sales revenue. HITL feedback helps fine-tune LLMs so that the outputs align with strategic business objectives. Human evaluators guide the model to focus on relevant tasks and adjust it to reflect shifting business priorities.
The ROI of RLHF and HITL Feedback for Enterprise LLMs
For data scientists and management teams, one of the most critical concerns is demonstrating the return on investment (ROI) when adopting new technologies. RLHF and HITL provide measurable business benefits, including:
Faster Time-to-Market
By incorporating RLHF and HITL feedback, enterprises can accelerate the deployment of LLMs. Human feedback ensures that models are continuously improved during training and after deployment, which reduces the time spent debugging and retraining models. This leads to:
- Reduced Development Costs: Enterprises can avoid costly trial-and-error cycles that often occur with traditional model training. By integrating human expertise, the models are more aligned with the desired outcomes from the outset.
- Streamlined Launches: With RLHF, models can be deployed sooner, with continuous human oversight enabling real-time adjustments, allowing businesses to scale faster than their competitors.
Increased Accuracy, Reduced Errors
Accuracy in LLMs can directly impact customer satisfaction, operational efficiency, and decision-making quality. By using RLHF, LLMs become better at making contextually relevant and accurate decisions, which drives the following:
- Improved Customer Satisfaction: LLMs that consistently provide accurate responses lead to better customer experiences, increasing customer loyalty and retention.
- Cost Savings: By preventing incorrect decisions or suboptimal outputs, RLHF and HITL can significantly reduce operational costs that arise from errors in automated processes.
Long-Term Value Creation
RLHF and HITL provide continuous improvement through ongoing human feedback. This means that over time, as the model interacts with new data and adapts to changes in the business environment, its performance improves. This provides long-term value that exceeds the initial investment and contributes to sustained business success.
Human-in-the-Loop Feedback: The Backbone of Scaling RLHF
Scaling RLHF requires a robust Human-in-the-Loop system to ensure continuous oversight, refinement, and monitoring. Here’s how HITL supports RLHF at scale:
1. Data Annotation and Labeling
At scale, high-quality data annotation is critical for model training. HITL ensures that data used for training is accurately labeled and contextually enriched, particularly in regulated industries like healthcare and finance.
2. Real-Time Model Validation
Once LLMs are deployed, HITL feedback ensures that outputs are continuously validated in real-time. This ensures that customer support, legal documents, and other outputs remain high-quality and aligned with human expectations.
3. Fine-Tuning Post-Deployment
After deployment, HITL ensures that the LLM remains aligned with evolving business goals. Continuous human feedback allows for the fine-tuning of LLM behavior, adapting it to shifting priorities and market demands.
4. Error Correction and Continuous Learning
HITL allows for rapid error correction. If an LLM makes a mistake or provides inaccurate results, humans can intervene immediately, providing feedback to correct errors and refine the model for future interactions.
Key Challenges in Scaling RLHF for Enterprise LLMs
While RLHF and HITL are powerful tools, scaling them across an enterprise presents its own set of challenges:
1. Resource Intensity
Human feedback is resource-intensive. As models scale, there’s an increasing need for qualified human evaluators to provide feedback. Enterprises must balance the human effort required for RLHF with the cost and time constraints of large-scale implementations.
2. Consistency and Quality Control
Maintaining consistent feedback can be challenging, especially when multiple evaluators are involved. Clear annotation guidelines and feedback protocols are critical to ensuring high-quality feedback and model reliability.
3. Managing Complex Use Cases
Enterprise LLMs often handle edge cases or rare scenarios that require specific human judgment. HITL systems must efficiently handle these cases by ensuring a well-organized feedback workflow that involves skilled annotators capable of interpreting complex situations.
How NextWealth Supports RLHF at Scale for Enterprise LLMs
At NextWealth, we specialize in scaling RLHF for enterprise-level LLMs with a human-centered approach. Our Human-in-the-Loop systems are designed to seamlessly integrate real-time human feedback with machine learning workflows, ensuring continuous improvement and adaptation to business needs.
We address the core challenges of RLHF at scale by:
- Optimizing human feedback workflows to minimize resource intensity.
- Implementing consistent feedback protocols to ensure the highest quality of data.
- Training expert annotators who bring industry-specific knowledge to the annotation process.
By leveraging NextWealth’s HITL expertise, enterprises can build LLMs that are accurate, ethically sound, and aligned with business objectives, ensuring long-term success and reliability.
Final Thoughts
Scaling RLHF with Human-in-the-Loop feedback is essential for building enterprise-level LLMs that are both accurate and adaptive. By integrating human insight with machine learning, businesses can create systems that not only meet current needs but are also resilient and capable of evolving with future challenges.
At NextWealth, we enable enterprises to navigate these challenges by providing structured, human-led annotation processes that ensure high-quality, reliable models. Our approach empowers businesses to deploy systems that are aligned with real-world requirements, leading to improved performance and sustained growth.
FAQ’s
1. How does Human-in-the-Loop (HITL) feedback improve LLM performance?
Human-in-the-Loop (HITL) feedback is a continuous process where human evaluators assess model outputs, provide corrections, and make adjustments. This process helps LLMs handle ambiguities, adapt to complex scenarios, and maintain ethical guidelines, ensuring the model delivers more reliable and relevant results tailored to the enterprise’s specific needs.
2. How does RLHF improve model accuracy and reduce errors in enterprise applications?
RLHF improves model accuracy by incorporating real-time human feedback that guides the model to produce more relevant, contextually appropriate, and accurate outputs. This feedback loop enables the model to adapt to changing business needs and correct mistakes as they arise, reducing errors and enhancing the model’s ability to handle complex tasks. In enterprise applications, this means more reliable customer service, better decision-making, and increased operational efficiency.
3. How does RLHF contribute to model adaptability in dynamic business environments?
RLHF allows enterprise LLMs to adapt to changing market conditions, evolving customer preferences, and industry trends by incorporating real-time human feedback. This continuous learning process ensures that the models can quickly adjust to new information, keeping the business responsive and competitive in a fast-paced environment.
4. Can RLHF and HITL help LLMs become more adaptable to changing customer needs and market trends?
Absolutely! RLHF and HITL make LLMs more adaptable by ensuring that human feedback is continuously incorporated into the model’s learning process. As customer needs, market trends, or regulatory requirements change, LLMs can quickly adjust their behavior to meet these new demands. By learning from real-time feedback, the model remains flexible and evolves in response to shifting business priorities, ensuring its long-term relevance and effectiveness.
5. What are the cost-saving benefits of using RLHF and HITL in enterprise LLMs?
RLHF and HITL contribute to cost savings by reducing the need for extensive manual corrections and retraining cycles. With continuous human feedback, models can learn more efficiently and make fewer errors, resulting in fewer costly mistakes down the line. Additionally, these techniques reduce the need for constant human intervention by automating processes while still maintaining high accuracy and ethical standards. This leads to improved productivity and lower operational costs in the long term