
Tag: am/ml
-
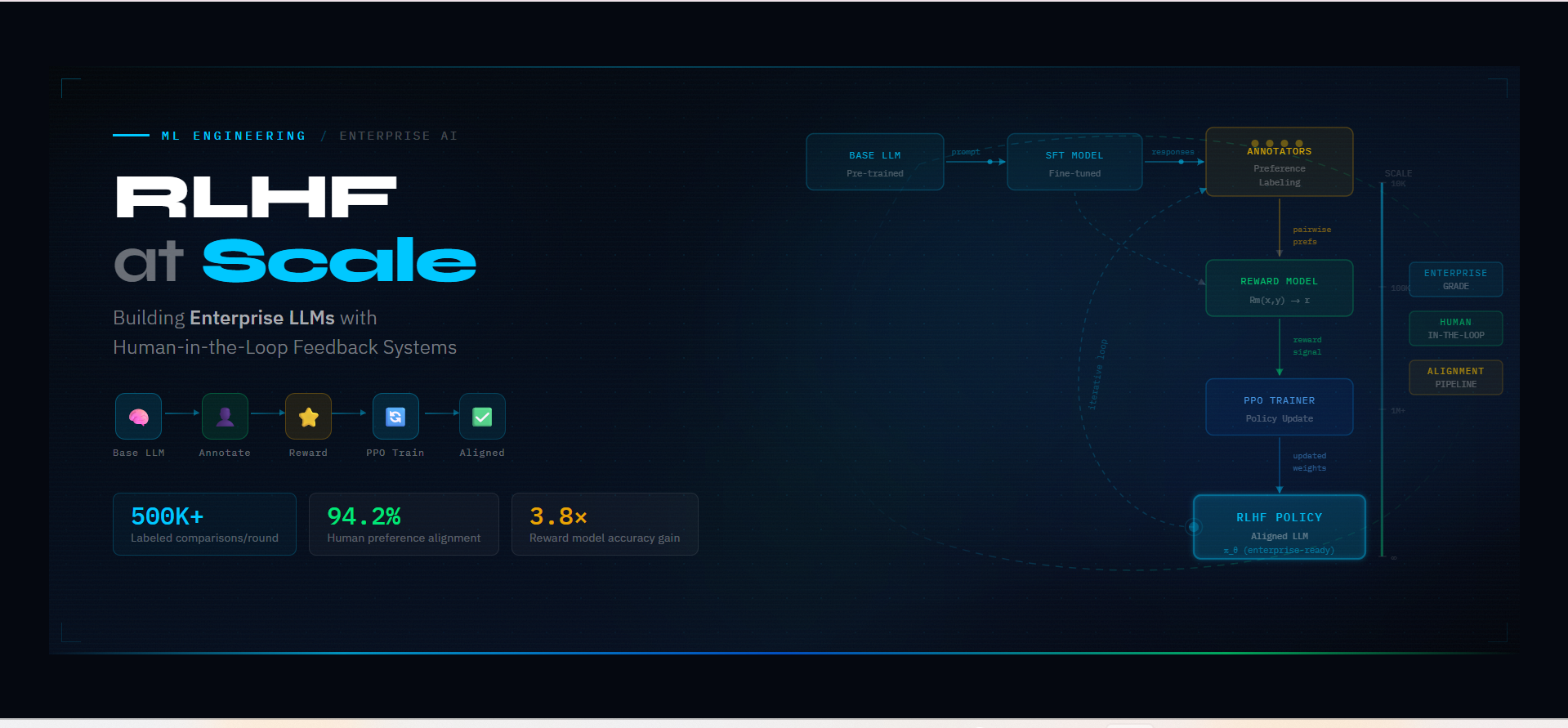
RLHF at Scale: Building Enterprise LLMs with Human-in-the-Loop Feedback
Quick Overview This blog delves into the importance of Reinforcement Learning from Human Feedback (RLHF) and Human-in-the-Loop (HITL) systems in building enterprise-level Large Language Models (LLMs). It outlines how integrating human feedback at scale enhances model accuracy, adaptability, and ethical decision-making. Key topics include: Key Points: In the world of enterprise-level Large Language Models (LLMs),…
-
Human Touch to AI : The Ground Truth Challenge
One of the key challenges for a Data Science team is the search for an accurately labelled dataset for solving the given problem. While it is easy to build a basic model that is reasonably accurate for a demo to the business, going beyond it towards a production worthy solution needs gold standard ground truth…