
As large language models (LLMs) evolve in scale and capability, evaluating their performance, safety, and applicability has become a critical concern. Globally, research has matured to incorporate multi-dimensional benchmarks addressing robustness, fairness, factuality, and task generalization across domains and modalities. Despite these advances, significant gaps remain in evaluating LLMs for low-resource languages particularly those in the linguistically diverse Indian context. This paper surveys the current landscape of LLM evaluation frameworks and highlights the urgent need for Indic-specific benchmarking. We propose IndicLLM-Eval, a contextualized evaluation framework that reflects the cultural, linguistic, and societal nuances of India, enabling equitable and safe deployment of LLMs across one of the most linguistically diverse populations in the world.
1. Introduction
Large language models (LLMs) like GPT-4, Claude, PaLM/gemini, and LLaMA have revolutionized natural language understanding and generation. However, evaluating their capabilities especially across a diverse set of real-world applications, remains a central challenge. Traditional NLP metrics such as BLEU or F1 fail to capture the complexity of LLM behavior, including contextuality, multi-turn reasoning, and socio-linguistic sensitivity.
While global benchmarks like HELM, MMLU, and BIG-bench have set the standard for English and high-resource languages, they fall short in addressing the intricacies of Indic languages. With 22 scheduled languages, hundreds of dialects, and complex socio-political contexts, India demands a new, culturally grounded approach to LLM evaluation.
2. Background: A Review of Existing LLM Evaluation Frameworks
To design meaningful benchmarks for Indic LLMs, it is necessary to understand the landscape of existing evaluation frameworks. Over the past few years, the research community has proposed a wide array of benchmarks to assess various facets of language model performance from general-purpose reasoning to domain-specific knowledge, and from safety testing to cultural sensitivity. This section offers a detailed review of these global frameworks, laying the groundwork for why a specialized Indic evaluation suite is required.
HELM: The Holistic Evaluation of Language Models (HELM) from Stanford provides a broad evaluation framework that assesses LLMs across multiple dimensions including fairness, calibration, robustness, and efficiency. HELM is particularly influential for its emphasis on standardizing comparisons across tasks and models.
MMLU: The Massive Multitask Language Understanding (MMLU) benchmark assesses general knowledge across 57 academic disciplines such as law, history, medicine, and philosophy. It is a staple benchmark for testing the breadth of LLM capabilities.
BIG-bench: Beyond the Imitation Game (BIG-bench) consists of over 200 tasks designed by a large community to evaluate LLMs on creative, ethical, and reasoning-based challenges that go beyond traditional NLP tasks.
HumanEval, LiveCodeBench: These benchmarks target code generation tasks. HumanEval evaluates functional correctness by executing code snippets, while LiveCodeBench integrates human evaluations and tests model performance in interactive coding environments.
FinBench, LegalBench, MultiMedQA: These are domain-specific benchmarks designed to evaluate models in finance, legal, and medical domains respectively. They assess the ability of LLMs to understand specialized vocabulary, structured documents, and perform expert reasoning.
SafetyBench, AgentHarm: These frameworks evaluate the safety of LLMs by prompting them with adversarial or harmful queries. SafetyBench focuses on social bias and toxicity, while AgentHarm evaluates harm potential in agent-based deployments.
M3Exam, CDEval: Both these benchmarks aim to evaluate multilingual and cultural competence in LLMs. M3Exam provides multilingual exam-style questions, while CDEval tests for alignment with diverse cultural norms.
LongBench, AdaLEval: These frameworks focus on long-context tasks, a critical ability for LLMs used in education, healthcare, or legal analysis. They test models’ ability to reason across long documents and follow multi-step instructions.
AILuminate, PromptBench: AILuminate, by MLCommons, introduces benchmarks for real-world safety, bias, and trust. PromptBench uses adversarial prompting techniques to measure model robustness and variation in generated outputs.
NIST, UK AI Safety Institute: These organizations are piloting public-sector evaluation frameworks to assess LLMs for national and international safety standards. They represent a shift toward regulatory benchmarking beyond academic research.
3. Research Gaps in Indic LLM Evaluation
Despite global progress in the evaluation of large language models (LLMs), substantial gaps persist when these methodologies are applied to Indic languages and contexts. These gaps are not only technical but deeply intertwined with linguistic diversity, socio-cultural complexity, and regional disparities in data availability. Below, we elaborate on the most critical limitations that currently hinder the accurate and fair evaluation of LLMs in India.
Limited Benchmark Coverage Across Indic Languages
A fundamental limitation of current LLM evaluation practices is the inadequate coverage of Indic languages in mainstream benchmarks. Most widely used evaluation datasets are heavily skewed toward English, Mandarin, and a small set of European languages, with Indic languages either absent or minimally represented. When included, coverage is typically restricted to high-resource languages such as Hindi, Bengali, or Tamil, leaving more than twenty constitutionally recognized Indian languages and hundreds of actively used dialects largely unaccounted for. This imbalance creates systematic blind spots in model assessment, resulting in performance claims that do not reflect real-world linguistic diversity or deployment conditions in India.
Inadequate Capture of Cultural Expressions and Linguistic Nuance
Language in India is inseparable from its cultural and social context. Yet, most existing benchmarks fail to reflect the intricate interplay of cultural expressions, idiomatic usage, honorifics, and regional dialectal differences that characterize Indic communication. For instance, expressions of politeness, familial hierarchy, and respect (through pronouns, verbs, or tone) vary dramatically between regions and even social strata. LLMs that are not evaluated on these subtle but essential elements risk producing content that is contextually incorrect, socially inappropriate, or even offensive. A culturally naïve evaluation methodology can therefore lead to flawed assumptions about model competence.
Data Scarcity, Imbalance, and Dialectal Fragmentation
Unlike English LLMs trained on terabytes of web content, Indic languages lack high-quality, diverse corpora. While Hindi and Bengali enjoy relatively larger datasets, many others like Oriya, Bodo, and Santali, suffer from data poverty. The IndicNLP corpus, for instance, offers just 2.7 billion words across 10 languages, half the size of some English-only datasets. Another major challenge is the large dialectal diversity within Indic languages. Languages like Hindi, Marathi, Assamese, and Bengali have dozens of regional variants, making it difficult to build datasets and evaluation benchmarks that generalize across dialects. The vast dialectal diversity across Indic languages means that geography and demography play a crucial role in data collection, as linguistic usage can vary significantly even within the same state or region
Fragmented Datasets and Inadequate Evaluation Metrics
Beyond data scarcity, existing Indic language datasets suffer from fragmentation and limited annotation quality. Many publicly available corpora are derived from English translations or constrained to formal domains such as government documents and news text, offering little coverage of conversational language, informal registers, or domain-specific usage. Annotations, where present, are often inconsistent or insufficiently validated, undermining their reliability for benchmarking.
Furthermore, evaluation practices rely predominantly on surface-level automated metrics such as BLEU, ROUGE, and F1-score. While useful for controlled generation or classification tasks, these metrics fail to capture semantic adequacy, pragmatic intent, discourse coherence, and sociolinguistic appropriateness dimensions that are particularly critical for morphologically rich and context-sensitive Indic languages. As a result, current metrics provide an incomplete and often misleading picture of model performance.
Absence of Safety and Harm Evaluation for Indic Social Contexts
Finally, existing LLM safety and bias evaluation frameworks are largely misaligned with the socio-political realities of India. While Western benchmarks emphasize racial or gender bias, they rarely account for harms arising from caste hierarchies, religious polarization, regional discrimination, or linguistic marginalization. These factors are deeply embedded in both historical and contemporary Indian discourse and can be subtly reproduced or amplified by LLMs.
The absence of Indic-specific adversarial prompts, bias taxonomies, and harm detection benchmarks means that models may pass standard safety evaluations while still generating content that reinforces stigma, misinformation, or intergroup hostility. Without evaluation methodologies grounded in Indian social contexts, claims of model safety and fairness remain incomplete and potentially misleading.
4. The Need for Indic-Specific LLM Evaluations and the IndicLLM-Eval Framework
While large language model (LLM) evaluation has advanced significantly in high-resource languages like English, there is a critical and urgent need to develop evaluation frameworks that address the linguistic and socio-cultural realities of India. The Indian subcontinent presents a uniquely complex linguistic ecosystem: it has over 20 constitutionally recognized languages, thousands of dialects, multiple scripts, and an extraordinary degree of intra-sentence code-mixing in daily communication. However, current global benchmarks are ill-equipped to assess LLM performance in such a multilingual, multicultural, and socially sensitive environment.
Indic languages are not merely translations of English they carry distinct syntactic structures, morphological patterns, honorifics, idioms, and expressions of hierarchy and social identity. Moreover, many Indian languages co-occur in conversation, often mixing with English (e.g., Hinglish, Tanglish, Benglish), creating hybrid language forms that require contextual reasoning and deep linguistic grounding. Without a benchmark that can capture these nuances, LLMs trained or fine-tuned for India will continue to be evaluated using proxies that do not reflect actual usage scenarios or safety considerations.
To address these challenges, we propose IndicLLM-Eval, a dedicated evaluation framework designed to benchmark the performance, fairness, safety, and usability of large language models in Indian linguistic contexts. The framework integrates culturally grounded tasks, multilingual support, and real-world datasets to ensure comprehensive and context-aware evaluation.
Components of the IndicLLM-Eval Framework
Press enter or click to view image in full size
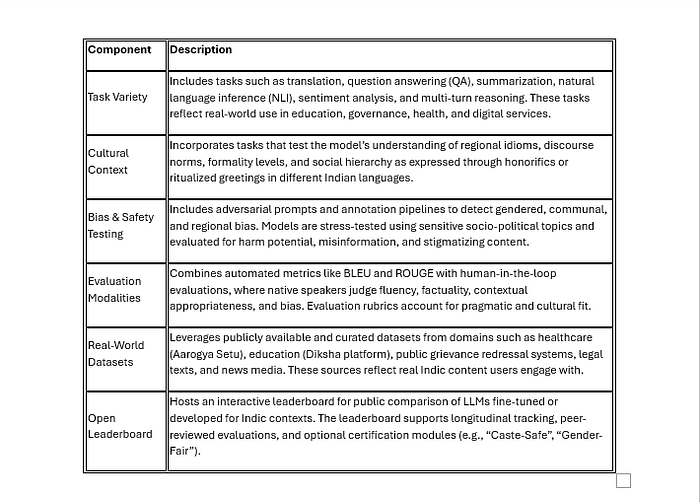
Core Design Principles
IndicLLM-Eval is grounded in the following design principles:
· Inclusivity: Prioritizes linguistic equity by evaluating across both high- and low-resource languages.
· Cultural Sensitivity: Tests for context-specific reasoning, including moral, religious, and familial domains.
· Human-Centricity: Emphasizes human judgment in assessing responses beyond numerical scores.
· Safety and Fairness: Builds on culturally contextualized definitions of harm and appropriateness.
· Modularity: Allows task-specific and domain-specific plug-ins for evaluating specialized use cases.
Why This Framework is Needed
India is becoming one of the largest deployment grounds for AI-powered systems from vernacular search engines to customer service bots in native languages. However, the lack of culturally aware and safety-conscious evaluation frameworks poses a real risk. Without robust assessments, LLMs may reinforce caste discrimination, misinterpret regional idioms, or produce biased content that undermines user trust. IndicLLM-Eval fills this void by setting rigorous standards that are aligned with Indian sociolinguistic realities and inclusive digital transformation goals.
IndicLLM-Eval Evaluation Pipeline
Evaluating language models in the multilingual and culturally diverse Indic context demands a specialized and structured approach. The IndicLLM-Eval pipeline is designed to systematically assess model performance across a range of tasks, languages, and sociolinguistic dimensions. It combines linguistic annotation, task-based benchmarking, human and automated evaluation, and bias auditing to ensure robust and responsible LLM development for India.
We summarize the process in the following seven steps:
Step 1: Input Data Collection
Curate diverse datasets across multiple Indic languages from domains like government records, social media, academic text, and conversational data, ensuring inclusion of both formal and informal registers.
Step 2: Linguistic Annotation & Code-Mix Parsing
Apply fine-grained linguistic annotations (e.g., POS tagging, NER) and parse code-mixed content to capture language switches, transliterations, and structural inconsistencies typical of multilingual Indian usage.
Step 3: Task Categorization
Organize the dataset into representative evaluation tasks:
- Question Answering (QA)
- Summarization
- Sentiment Analysis
- Natural Language Inference (NLI)
- Dialogue Understanding
Step 4: Evaluation Modules
Deploy a multi-layered evaluation strategy:
- Automated Metrics (BLEU, ROUGE, Accuracy)
- Human Judgments (fluency, coherence, factual consistency)
- Bias Audit (gender, caste, religion, regional)
- Long-Context Testing (retention, coherence in extended documents)
Step 5: Score Aggregation & Reporting
Aggregate results across tasks and metrics into composite scores. Present detailed performance profiles for transparency and comparability.
Step 6: Leaderboard + Safety Certification
Publish model rankings on a public leaderboard and assign Safety Certifications based on compliance with ethical and bias mitigation benchmarks.
Step 7: Feedback loop
This completes the loop and feeds into the input data collection step1.
5. Future Research Directions
To ensure the development of robust and inclusive language models for the Indian subcontinent, future research must address several critical and underexplored areas:
1. Handling Real-World Indic Tasks with Complex Linguistic Structures
Many existing benchmarks focus on short-form or simplified tasks that do not represent the actual usage of language models in Indic contexts. However, real-world tasks in India often involve:
Lengthy legal, bureaucratic, or policy documents that require comprehension, summarization, and translation.
Multi-step instructions in contexts like government schemes, rural outreach programs, or educational content delivery.
Multi-turn dialogue systems, especially in public service chatbots, citizen grievance redressal, and health or education helplines.
Future benchmarks must design and evaluate tasks that reflect these complexities, including long-context understanding, instruction-following under ambiguity, and context-aware dialog continuation.
2. Cross-Lingual Transfer and Resource Efficiency in Low-Resource Indian Languages
Most Indic LLMs are trained on relatively better-resourced languages like Hindi, Bengali, or Tamil. However, over 20 Indian languages have minimal digital presence. Key research questions include:
Can knowledge transfer be achieved from high-resource to low-resource Indic languages using techniques like adapter tuning, multilingual embeddings, or meta-learning?
How effective are zero-shot or few-shot approaches in languages like Maithili, Bodo, Santali, or Konkani?
How can tokenizer design, vocabulary alignment, and shared syntax across Indo-Aryan or Dravidian languages be leveraged to minimize compute cost and improve model accessibility?
Such work is crucial for democratizing NLP capabilities across linguistic communities.
3. Detecting and Auditing Socio-Cultural Bias in Indic LLMs
Bias mitigation remains insufficiently addressed in the Indian context. Indian society is marked by nuanced hierarchies and sensitivities around:
Caste-based microaggressions, which may be implicit and culturally coded.
Gendered norms and occupational roles, often reflected in stereotypical completions.
Regional and linguistic favouritism, where some states or dialects are overrepresented or idealized.
A research frontier lies in designing adversarial prompt sets and bias stress-tests rooted in lived Indian realities. These should be co-developed with sociologists, political scientists, and civil society groups to surface latent harms and propose mitigation strategies.
4. Multimodal and Multiscript Evaluation for Richer Indic Communication
Indic communication is not just textual. It frequently blends:
Scripts like Devanagari, Tamil, Telugu, Urdu, and even Romanized forms (e.g., Hinglish).
Images and scanned documents with handwritten or printed Indic scripts common in administrative workflows.
Speech, which is a primary communication mode for millions with limited literacy.
Future benchmarks must include multimodal tasks such as:
OCR and script identification across Indic languages.
Speech-to-text and text-to-speech in multilingual scenarios.
Document classification and extraction from scanned PDFs or mobile camera captures.
Evaluating multimodal LLMs (e.g., Gemini, GPT-4o, Kosmos-2) on these tasks will align models closer to real deployment needs in Indian contexts.
5. Participatory Benchmarking and Cultural Grounding via Expert Inclusion
The development of truly representative benchmarks requires a participatory design approach involving:
Native speakers, who can provide language-specific nuance, idiomatic expressions, and regional relevance.
Linguists and anthropologists, who understand the socio-cultural underpinnings of language use in India.
Domain experts in law, education, public health, or agriculture, who can curate tasks that reflect real-world workflows.
Such stakeholder involvement ensures that model evaluation is culturally grounded, ethically robust, and practically useful. This direction also aligns with decolonial approaches to AI development that respect linguistic plurality and community agency.
Summary
To move beyond token-level accuracy and generalized benchmarks, Indic NLP research must embrace the linguistic diversity, cultural complexity, and technical needs of Indian society. By focusing on these research directions contextual richness, low-resource equity, socio-cultural fairness, multimodal inclusivity, and participatory design we can shape a future where LLMs serve all of India, not just a privileged linguistic elite.
6. Conclusion
The IndicLLM-Eval framework emerges as a critical response to the limitations of current large language model (LLM) evaluation methodologies, which despite significant global progress fall short when applied to India’s multilingual, socio-culturally diverse, and resource-constrained environments. Existing benchmarks often overlook the unique challenges posed by Indian languages, such as code-mixing, multi-script representation, low-resource availability, and culturally embedded linguistic patterns.
To be truly impactful, IndicLLM-Eval must go beyond narrow accuracy metrics and build toward a sustainable, adaptable evaluation ecosystem. This includes designing computationally efficient yet robust metrics suitable for deployment in rural and edge settings, where infrastructure constraints are significant. Evaluation must retain depth and rigor while being lightweight enough for real-world, low-resource applications.
By focusing on contextual richness, low-resource generalization, socio-cultural fairness, multimodal inclusivity, and participatory benchmarking, IndicLLM-Eval sets a new standard for language model evaluation. These pillars are essential not only for improving performance in Indian languages but also for aligning AI systems with the values and realities of their users.
Furthermore, this framework is not India-exclusive. Its principles offer a transferable blueprint for other multilingual, low-resource, and culturally complex regions seeking fair, inclusive, and meaningful model evaluations.
As India scales its AI ambitions, equitable and context-aware model evaluation is no longer optional — it is foundational. The path forward requires a concerted research agenda that bridges linguistic diversity with technical innovation, ensuring that future AI systems are trustworthy, representative, and ready for deployment at scale.