

Precision LiDAR & 3D Point Cloud Annotation Services
Automotive-Grade Precision for Autonomous Vehicle and ADAS AI Systems
NextWealth delivers production-scale LiDAR point cloud annotation, 3D bounding box labeling, radar annotation, and sensor fusion labeling for autonomous vehicle OEMs, ADAS developers, and robotics companies. With 4M+ annotated multi-modal frames and 99.3% cross-sensor accuracy across delivery centers in 11 cities across India, we combine advanced tooling with expert human-in-the-loop quality to build training datasets that meet the precision demands of real-world 3D perception systems.
| Metric | NextWealth Benchmark | Industry Context |
|---|---|---|
| Annotated multi-modal frames | 4M+ | Production-scale delivery |
| Cross-sensor accuracy | 99.3% | Across LiDAR + camera fusion tasks |
| Delivery centers | 11 cities in India | Tier-2 model, 5,000+ specialists |
| Supported file formats | PCD, LAS, ROS bag | Standard AV pipeline formats |
| Workforce composition | Women-first workforce | Trained domain specialists |

Core LiDAR Annotation & Labelling Services
The following annotation methodologies are supported across all major autonomous driving and robotics pipeline architectures.
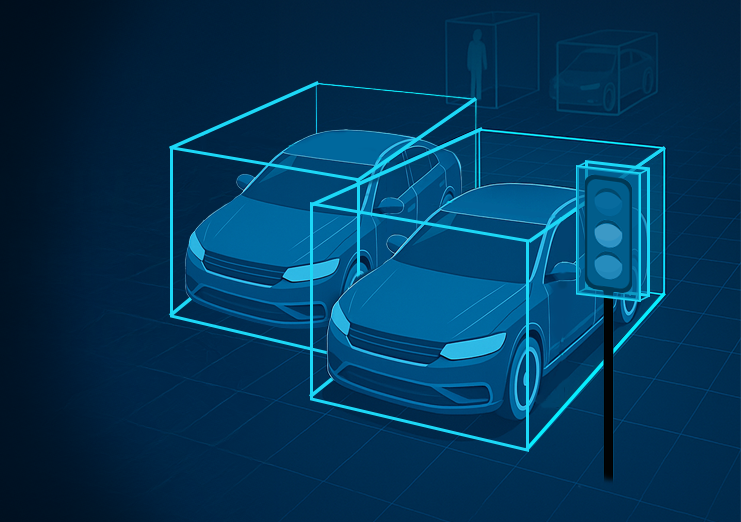
3D Bounding Box (Cuboid) Annotation
Annotators place tight 3D bounding boxes around objects in LiDAR point clouds — vehicles, pedestrians, cyclists, and static obstacles — with precise orientation, dimension, and heading angle attributes. Annotation is validated for temporal consistency across frames to support object tracking pipelines. This is the foundational task for object detection models in Level 2 through Level 5 AV systems.
Semantic Segmentation
Each point in the LiDAR dataset is classified at the point level — drivable surface, lane markings, vehicles, pedestrians, vegetation, buildings, and infrastructure. Point-level semantic labels provide AI models with context-rich environmental understanding required for scene parsing, HD map generation, and occupancy grid modeling.


Polygon & Polyline Annotation
Lane boundaries, curbs, guardrails, road edges, and irregular infrastructure are traced with polygon and polyline annotations. This supports lane-keeping assist systems, intersection navigation, and boundary detection in mixed traffic environments. Annotation is performed at the 2D image plane and cross-referenced with corresponding LiDAR frames in fusion workflows.
Landmark & Key-point Annotation
Structural and semantic key points — traffic signs, signal heads, road markers, and infrastructure anchors — are annotated for localization and mapping tasks. Key-point annotation also supports camera-to-LiDAR calibration validation workflows and is used in robotic manipulation pipelines for grasp planning.


Sensor Fusion Annotation
LiDAR point clouds are aligned and co-annotated with RGB camera frames, radar returns, and IMU data to produce synchronized multi-modal training datasets. Fusion annotation supports cross-modal learning architectures — including late fusion, early fusion, and attention-based transformer models — that require consistent labeling across sensor modalities. Calibration drift and timestamp misalignment are validated as part of the annotation quality workflow.
Radar Annotation
Radar returns are annotated for object detection, velocity estimation, and range classification — particularly for low-visibility and adverse weather scenarios where LiDAR performance degrades. Radar annotation is delivered alongside LiDAR and camera labels for full sensor suite training dataset construction.

Supported File Formats and Tool Integrations
A global autonomous vehicle OEM engaged NextWealth to support the expansion of its Level 4 pilot program across new geographic markets — requiring annotated LiDAR training data that reflected diverse road conditions, traffic behavior, and infrastructure patterns not represented in existing training sets.

File Format Support
- PCD (Point Cloud Data) — the standard format for raw LiDAR sensor output, supported across all major lidar hardware vendors including Velodyne, Ouster, and Hesai
- LAS / LAZ — standard geospatial point cloud formats used in surveying, HD mapping, and infrastructure inspection workflows
- ROS bag — Robot Operating System bag files capturing multi-sensor time-series data; supported for autonomous vehicle and robotics training dataset construction
- PLY, E57, and binary PCD variants — supported on request for specialized hardware or legacy pipeline compatibility
Annotation Tool Integrations
- Segments.ai, Supervisely, CVAT, etc supported as annotation environments where client pipelines require specific tooling
- Custom annotation tooling integration available for enterprise clients with proprietary labeling infrastructure
- Delivery in JSON, XML, and CSV label formats compatible with major ML training frameworks

Client Case Study: Autonomous Vehicle OEM — Obstacle Detection at Scale
A global autonomous vehicle OEM engaged NextWealth to support the expansion of its Level 4 pilot program across new geographic markets — requiring annotated LiDAR training data that reflected diverse road conditions, traffic behavior, and infrastructure patterns not represented in existing training sets.
Scope and Methodology
- 500,000+ multi-sensor annotated LiDAR frames delivered across six months of continuous production
- 3D bounding box annotation for vehicles, pedestrians, cyclists, and static obstacles with full orientation and heading attributes
- Sensor fusion annotation synchronizing LiDAR point clouds with RGB camera frames and radar returns
- Temporal consistency validation across frame sequences to support object tracking pipeline stability
- Weekly quality audits with Cohen’s Kappa inter-annotator agreement measurement; minimum threshold maintained above 0.85 throughout the project
Measurable Outcomes
- Cross-sensor annotation accuracy maintained at 99.1% across the full delivery volume
- Pedestrian and cyclist recall — the safety-critical recall metric — held above 98.7%, meeting the client’s functional safety annotation specification
- Temporal consistency score above 96% across frame sequences, reducing tracking model instability in subsequent training runs
- Turnaround maintained within agreed SLA across all six months, supporting the client’s Level 4 pilot expansion timeline
- This engagement reflects NextWealth’s capacity to deliver automotive-grade annotation quality at production volume — with quality metrics that align directly with the functional safety and perception reliability requirements of Level 4 AV development programs.

Quality Benchmarks and HITL Metrics
Human-in-the-loop quality in LiDAR annotation is not adequately measured by overall accuracy alone. The following task-specific metrics govern annotation quality at NextWealth:
| Annotation Task | Primary Quality Metric | Why This Metric Matters |
|---|---|---|
| 3D Bounding Box / Cuboid | Precision + IoU threshold | False positives corrupt object detection class boundaries |
| Semantic Segmentation | Mean IoU (mIoU) | Point-level errors propagate across scene understanding models |
| Sensor Fusion Alignment | Cross-sensor precision + recall | Misaligned labels degrade multi-modal embedding quality |
| Temporal Consistency | Frame-to-frame consistency score | Tracking model stability depends on label continuity |
| Compliance / Safety-Critical Objects | Recall + Critical Error Rate | Missed annotations in safety-critical classes carry functional safety implications |
| Inter-Annotator Agreement | Cohen’s Kappa | Label inconsistency between annotators creates contradictory training signals |
All annotation batches are subject to a minimum sampling QA review, with escalation protocols for safety-critical object classes including vulnerable road users (pedestrians, cyclists) and dynamic obstacle tracking.
Autonomous Vehicles & ADAS


- Supported Level 4 and Level 5 pilot programs with temporal consistency across LiDAR and camera fusion annotation
- Delivered obstacle detection, pedestrian tracking, and lane recognition training datasets for global AV OEM programs
Smart Cities & Infrastructure

- Generated 3D urban maps for semi-urban road environments to support traffic optimization and intelligent infrastructure planning
- Delivered annotated LiDAR datasets for municipal smart city projects across traffic management and urban planning applications
Robotics & Industrial Automation
- Annotated dense LiDAR point clouds with hazard detection markers enabling autonomous warehouse robot navigation
- Supported industrial automation clients in reducing operational downtime through precise obstacle recognition datasets
Geospatial & Surveying

- Processed 2M+ LiDAR frames for a European surveying firm, reducing annotation turnaround from weeks to days
- Delivered terrain classification and environmental monitoring datasets at production scale
Railways & Transportation
![]()
- Annotated 80,000+ km of railway assets — tracks, poles, signals, overhead wires — using LiDAR and panoramic imagery
- Improved asset management efficiency by 40%, supporting predictive maintenance and safety compliance programs
Agriculture & Forestry

- Supported precision irrigation projects by mapping farmlands and elevation shifts with annotated LiDAR data.
- Enabled crop density monitoring and vegetation analysis for large-scale agri-tech platforms.
Security & Defence

- Assisted defence partners in annotating LiDAR datasets for perimeter surveillance and low-visibility threat detection.
- Delivered annotated terrain awareness maps that improved border security monitoring efficiency.





Visual Annotation (Driver Monitoring via Camera)
- Head Pose & Gaze Annotation: Labeling where the driver is looking (road, dashboard, phone, mirrors).
- Facial Expression Annotation: Drowsiness, yawning, distraction, anger, stress, smoking, talking.
- Eye State Annotation: Open/closed, blink rate, eye closure duration.


Audio Annotation (If In-cabin Audio is Captured)
- Voice Activity Detection: Speaking, shouting, talking on phone.
- Emotion Annotation (Speech-based): Calm, angry, stressed, distracted.
- External Sounds Annotation: Honking, sirens, sudden loud noises that may affect driver behavior.


Sensor / Telemetry Annotation
- Driving Event Labeling: Hard braking, rapid acceleration, sharp turns, overspeeding.
- Risky Manoeuvre Annotation: Tailgating, lane departure, sudden swerves.
- Distraction & Inattention Events: Identified from steering, brake, or accelerator patterns.
- Fatigue Detection Signals: Micro-corrections in steering, delayed reactions.


Environment & Context Annotation
- Traffic Condition Annotation: Dense traffic, clear road, pedestrian presence.
- Weather/Lighting Condition Annotation: Rain, fog, night/day (to see if behavior changes).
- Road Type Annotation: Highway, city streets, rural roads.


The Next Frontier of Data Annotation: Structuring the Complex Pipelines Powering 2026 AI Models
5 mins read
Latest Update




