

The global data annotation and labeling service market is undergoing explosive growth, valued at ~USD 6.5 billion in 2025, and projected to grow at a CAGR of ~25% over the next five years. Depending on the segment, it is expected to reach 19.9 billion by 2030—source – Mordor Intelligence

According to industry reports, up to 80% of an AI project’s time is spent in data preparation tasks, including labelling, annotation, cleaning, and validation, making it the most resource-intensive phase of the AI lifecycle. Source – The Sequence
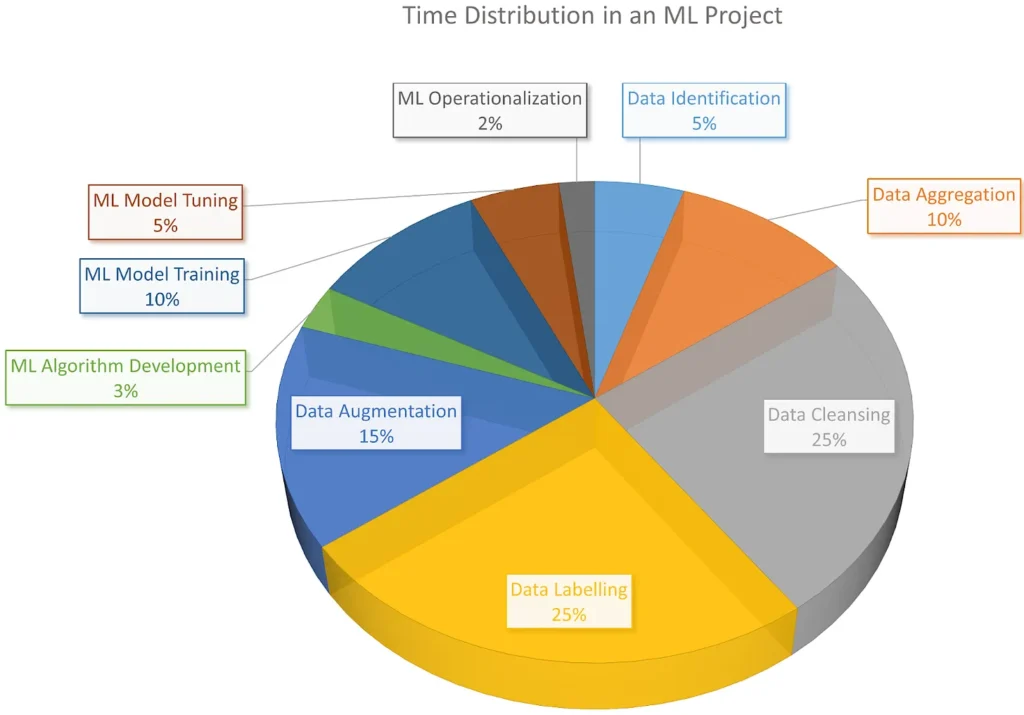
Together, these trends underscore a growing realization in the AI industry: model performance is only as good as the data it learns from. Choosing between basic labeling and annotation workflows isn’t just a technical decision—it’s a strategic one that can shape the success (or failure) of your model deployment.
So, what is data labelling & annotation?
Data Labelling –
Data labelling refers to the process of assigning predefined identifiers, such as tags, categories, or values, to raw datasets, enabling machine learning models to understand and learn from structured input. Labelling is most often used in supervised learning tasks, where each data point needs a clear and specific output for the model to mimic during training.
While labelling is foundational for training AI models, it typically deals with simple, high-level classifications without adding contextual or spatial information. This is why discussions about data annotation vs data labeling have become central to AI development.
Examples of Data Labelling (Structured by Data Type)
Text Data
- Sentiment Analysis: Labelling customer reviews or feedback as positive, neutral, or negative for brand sentiment tracking.
- Intent Detection: Categorizing chatbot queries as billing issues, product inquiries, cancellation, etc., to enable intelligent response routing.
- Topic Classification: Tagging news articles or blog posts as finance, healthcare, sports, etc., for content curation.
- Toxicity & Abuse Detection: Identifying harmful content by labeling as hate speech, harassment, or safe for moderation tools.
Image Data
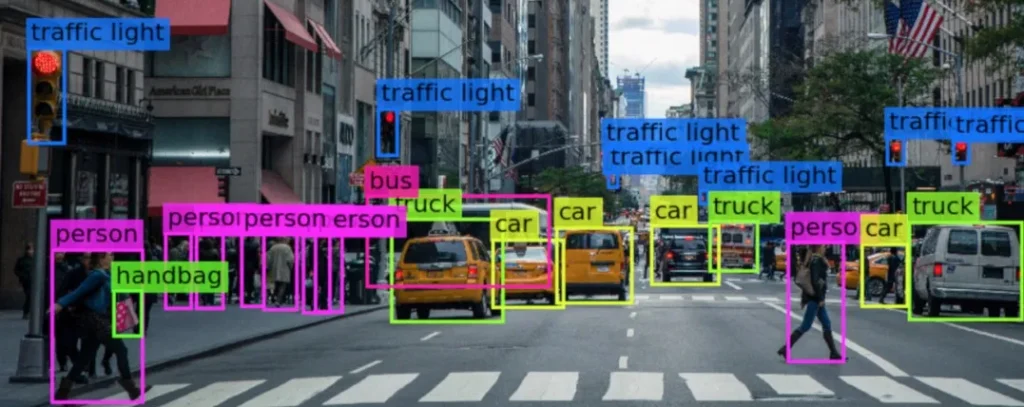
- E-commerce Product Categorization: Labelling clothing images as t-shirt, dress, sneakers, etc., for catalog automation.
- Medical Imaging: Tagging X-rays or MRIs as benign, malignant, or normal to support diagnostic models.
- Wildlife Monitoring: Labelling animal camera trap images as deer, leopard, human, etc., for conservation analytics.
- Satellite Imaging: Classifying regions as urban, agricultural, water, or forest for land-use applications.
- Vehicle Detection: Tagging traffic camera images with vehicle types like sedan, truck, or motorcycle.
Video Data
- Surveillance Footage Analysis: Labelling clips with actions like trespassing, normal activity, or loitering for public safety systems.
- Sports Analytics: Tagging key events such as goals, fouls, or offside for highlight generation and performance review.
- Driver Monitoring Systems: Tagging actions like drowsy, distracted, or alert for ADAS safety applications.
Audio Data
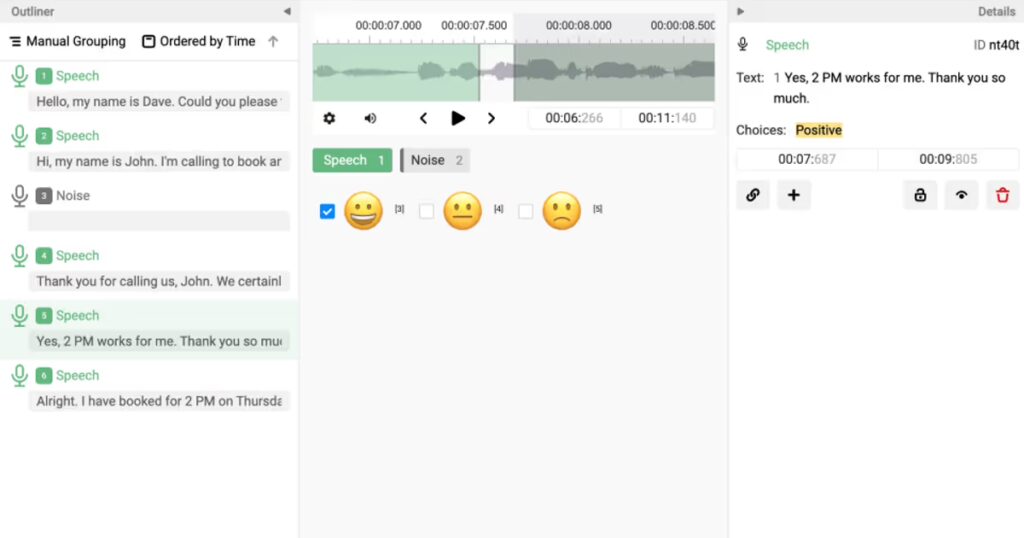
- Customer Support Monitoring: Labelling call center recordings as angry, calm, frustrated, etc., for agent training and satisfaction analysis.
- Environmental Sound Detection: Classifying sounds like siren, glass break, dog bark, or applause for smart city or home use.
- Speaker Identification: Labelling voice segments as Speaker A, Speaker B, or unknown in interviews or meetings.
- Emotional Tone Detection: Tagging vocal tones as happy, sad, anxious, etc., for mental health screening or voice assistants.
What is Data Annotation?
Data annotation is a broader process that involves enhancing raw data with detailed information, metadata, or contextual insights that help AI models understand not just what something is, but also where it is, how it relates to other elements, and why it matters within the data structure. It supports a wide range of complex AI applications, especially in domains like computer vision, natural language processing, and speech recognition. In practice, data labeling and annotation often go hand-in-hand, with labeling handling classification tasks and annotation providing context, structure, and deeper meaning.
Examples of Data Annotation

{kind=link}
- Object Detection: Drawing bounding boxes around multiple objects such as cars, pedestrians, or traffic signs in an image.
- Semantic Segmentation: Outlining each object at the pixel level to help models understand boundaries between objects.
- Keypoint Annotation: Marking key landmarks on objects or faces (e.g., eyes, joints) for pose estimation or facial recognition.
- Text Annotation
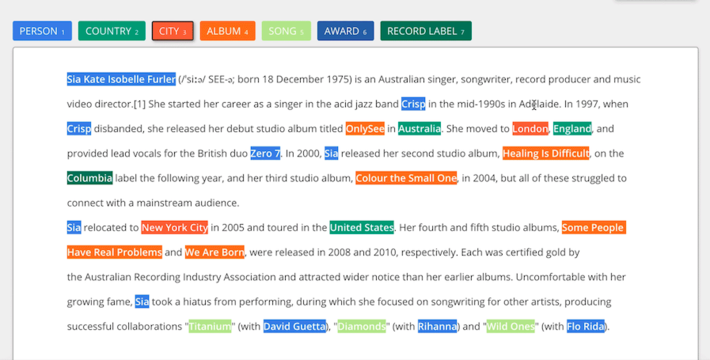
- Named Entity Recognition (NER): Highlighting named entities like “John Smith” (Person), “London” (Location), “Google” (Organization).
- Part-of-Speech Tagging: Assigning grammatical roles (noun, verb, adjective) to each word in a sentence.
- Coreference Resolution: Linking pronouns or phrases back to their referenced entities (e.g., “She” referring to “Dr. Singh”).
- Intent and Slot Annotation: Tagging user input to detect intent (e.g., book flight) and extract slots (e.g., destination: Paris).
- Audio Annotation
- Speech Transcription with Timestamps: Annotating start and end times of each word or phrase in audio recordings.
- Speaker Diarization: Identifying “who spoke when” in multi-speaker audio, such as meetings or interviews.
- Object Tracking: Tracking the same object across multiple frames for motion detection or behavior prediction (e.g., tracking a person in a security video).
- Activity Recognition: Annotating actions over time, such as running, sitting, waving, or falling—used in sports analytics, surveillance, or gesture recognition.
- 3D Point Cloud Annotation
- 3D Object Labeling: Drawing 3D cuboids around objects in LiDAR data, such as cars or pedestrians, for autonomous vehicle perception.
- Instance Segmentation: Separating different instances of similar objects in 3D space (e.g., multiple trees in forestry scans).
- Spatial Relationship Annotation: Tagging positional context like distance and orientation between annotated elements (e.g., vehicle behind cyclist).
Comparison: Data Labeling vs Data Annotation
| Aspect | Data Labeling | Data Annotation | Clarification |
| Definition | The process of assigning simple, predefined labels (e.g., categories or classes) to data. | The process of adding descriptive metadata or structure to data, including labels, positional markers, relationships, and contextual elements. | Annotation is a broader concept that includes labelling. All labelled data is annotated, but not all annotations are labels. |
| Purpose | To provide examples of correct outputs for a model to learn in supervised learning tasks. | To enable models to interpret complex or unstructured data by providing semantic, structural, or spatial context. | Labelling answers “what is this?” while annotation answers “what is it, where is it, and how is it connected?” |
| Task Type | Classification tasks with predefined outputs (e.g., spam detection, sentiment tagging). | Interpretation tasks involving relationships, spatial localization, sequences, or temporal data. | Labelling supports foundational ML training; annotation supports perception-based or context-driven AI systems. |
| Examples | Image: Classifying images as “cat” or “car” Text: Labelling sentiment as “positive” or “negative” Audio: Tagging clips as “speech” or “music” |
Image: Drawing bounding boxes around vehicles Text: Tagging named entities such as “Apple” as ORGANIZATION Video: Tracking a person frame-by-frame Audio: Timestamping speakers in a dialogue |
Labelling assigns a class or tag; annotation defines additional structure, such as position, timing, or meaning. |
| Common Use Cases | Email classification, content moderation, product categorization, and basic sentiment analysis. | Object detection, semantic segmentation, named entity recognition (NER), medical image annotation, speech diarization, and video frame labelling. | Annotation is required for advanced computer vision, NLP, and audio processing tasks. |
| Data Types Supported | Structured and semi-structured data, including text, images, audio, and tabular data. | Unstructured and complex data, including text, images, videos, audio, 3D point clouds, and multimodal datasets. | Annotation supports richer data modalities and task types, enabling spatial and temporal understanding. |
| Complexity | Low to moderate; typically, task-driven and easily scalable. | Moderate to high; often requires trained annotators and domain expertise. | Annotation demands more time and expertise but improves model generalization and downstream accuracy. |
| Automation Potential | High labelling can be assisted with rule-based systems, pre-trained models, or crowdsourcing. | Moderate; some annotation tasks can be pre-filled with models but still require manual review and correction. | Human-in-the-loop is critical for most annotation workflows to ensure accuracy and context fidelity. |
| QA Needs | Basic validation through spot checks or majority-vote consensus. | Requires structured review layers, inter-annotator agreement, and benchmark (gold set) comparisons. | Quality issues in annotation can significantly impact training performance and model outputs. |
| AI Readiness Level | Suitable for training basic or intermediate models (e.g., linear classifiers, early-stage neural networks). | Required for training complex models such as CNNs, RNNs, transformers, LLMs, and multimodal architectures. | Annotation plays a critical role in advanced AI systems, including autonomous vehicles, medical AI, and foundational models. |
Evolving Trends in Annotation & Labelling: Architecting Data for Scalable AI
As AI transitions from R&D to real-world deployment, annotation strategies must evolve to match the scale, speed, and precision that modern models demand. The next frontier in annotation isn’t just about tagging data, it’s about engineering feedback-rich, simulation-ready, and model-adaptive data ecosystems.
- Synthetic Data Becomes Foundational
Simulation engines (e.g., Unity, Unreal, AirSim) are now core infrastructure for generating high-fidelity, auto-labeled datasets, especially where real-world capture is risky, rare, or privacy-restricted.
- Enables edge case coverage at scale (e.g., accidents in AV training)
- Powers safety-critical ML in robotics, defense, and medical imaging
- Often combined with real-world fine-tuning for generalization
- Active Learning Pipelines Outperform Static Workflows
Modern pipelines are moving toward model-driven annotation, where ML systems surface ambiguous or high-impact samples for targeted review.
- Reduces label volume by 40–70% while maintaining model accuracy
- Integrates with uncertainty estimation, ensemble disagreement, and entropy scoring
- Supports closed-loop retraining and faster production cycles
- Foundation Models Enable Semi-Automated Labeling
LLMs (e.g., GPT-4, Claude) and vision backbones (e.g., SAM, CLIP, DINOv2) are now used as pre-annotators—especially in bootstrap phases or when building few-shot generalizers.
- Cuts human effort by 2–5x with prompt-driven label suggestion
- Requires expert QA to mitigate hallucination or bias
- Key for bootstrapping large-scale NLP and vision tasks
- 3D + Multimodal Annotation is Now a Core Requirement
AI systems increasingly require spatial, temporal, and sensory context. This is especially true in:
- Autonomous navigation (LiDAR, radar, stereo vision)
- AR/VR object and hand tracking
- Cross-modal LLMs combining image, video, text, and audio inputs
What’s Driving the Growth of Data Annotation & Labeling?
- AI’s Rapid Expansion Across Industries
As AI adoption explodes in sectors like healthcare, finance, retail, and autonomous systems, the need for high-quality, labeled datasets is skyrocketing. Each domain brings new data types — from clinical scans to 3D LiDAR — requiring tailored annotation workflows.
- New Use Cases & Data Types
Annotation is expanding well beyond 2D images. Organizations are now labeling video, audio, 3D point clouds, and even multimodal fusion data for AR/VR, robotics, and digital twins. Emerging applications in security, predictive analytics, and metaverse content are driving demand
- Trust, Regulation & Explainability
With the rise of AI regulation (GDPR, EU AI Act, etc.), companies are being held accountable for how data is sourced and labeled. High-quality annotation isn’t just for accuracy — it’s for auditability, fairness, and explainability.
Accurate, transparent annotation helps prevent bias and ensures ethical compliance.
- Shift to Data-Centric AI
Leaders like Andrew Ng have emphasized it clearly: we’ve optimized our models — now it’s time to optimize our data. That’s making annotation a strategic priority, not just a back-office task.
Key Takeaways & Strategic Conclusion
- Data Quality Outperforms Model Tweaks
Despite accelerated innovation in model architectures, refining data yields bigger gains. As Andrew Ng explains, moving from a model-centric to a data-centric AI approach systematically improving data qualitye nables more reliable performance with fewer iterations Data-centric AI Resource Hub+2MIT Sloan+2LandingAI+2LandingAI.
“Instead of focusing on the code, companies should develop systematic engineering practices for improving data in reliable and efficient ways.” LandingAI
- Annotation Is Strategic Infrastructure
Annotation isn’t just preparatory work, it’s infrastructure. The rise of synthetic data, model-in-the-loop labeling, active learning, and foundation model–assisted workflows reflect a strategic shift toward intelligent, context-aware pipelines that are essential for robust AI.
- Choose the Right Method—Labeling vs. Annotation
- Labeling is best for high throughput, clear-cut classification tasks.
- Deep annotation is essential for training perception systems, multimodal LLMs, medical AI, autonomous systems, and any model where spatial or contextual nuance matters.
This is not just an operational choice—it’s a foundational architecture decision. Experts highlight that the most effective AI strategies combine data annotation and labeling, applying each method where it adds the most value across the project lifecycle.
- Human-in-the-Loop (HITL) Remains Essential
Automated systems still falter in edge cases and high-risk scenarios. HITL ensures resilience by introducing human judgment where ambiguity exists. Stanford HAI underlines that the future of reliable AI depends on keeping humans in charge, not just in the loop.
Why NextWealth is the Right Partner for Data Labeling & Annotation Requirement
As AI systems evolve from proof-of-concept to production-grade, the stakes for data quality, security, and scalability rise exponentially. NextWealth stands at this intersection—where domain expertise meets data operational excellence.
What Sets NextWealth Apart:
Human-in-the-Loop Precision at Scale
We don’t just offer annotation—we engineer it. Our human-in-the-loop workflows are powered by highly skilled teams trained across complex domains like medical imaging, AV perception, financial risk modeling, and multilingual NLP. Every output passes through multi-layered QA loops, driving precision even in edge cases.
Advanced Tech Stack + Secure Infrastructure
NextWealth leverages modern annotation platforms integrated with:
- Active learning pipelines
- AutoML feedback loops
- LLM-assisted pre-annotation
This accelerates turnaround without compromising control. Our ISO 27001-compliant facilities and client-dedicated delivery centers ensure enterprise-grade security and data governance.
Domain-Ready Workforce with Deep Specialization
We combine process rigor with domain literacy. Whether you’re training a cardiology detection model, an autonomous navigation stack, or financial fraud classifier, our curated workforce delivers relevance and accuracy from day one
Scalable, Cost-Efficient Delivery
NextWealth balances cost, quality, and speed. Our unique model supports high-volume annotation for AI programs at scale, without ballooning your internal teams or timelines.
NextWealth is not just a vendor; we’re your strategic data operations partner—embedding ourselves into your AI lifecycle to reduce rework, de-risk model drift, and compress time-to-deployment.
Final Thought: Build the AI You Want—With the Data It Deserves
As foundation models mature and data modalities diversify, the competitive edge no longer lies in model architecture, but in data craftsmanship.
Data Annotation and labelling are no longer tactical steps. They’re strategic investments in your AI’s resilience, explainability, and long-term performance. Choosing the right partner isn’t just about execution—it’s about co-architecting a data-first AI operating system.
Your models are only as good as the data they’re built on.
With NextWealth, you don’t just label data—you elevate it.
Frequently Asked Questions
1. Data Annotation vs Data Labeling: What’s the difference?
Data labeling is the process of assigning simple tags or categories to data, often used in supervised learning tasks. Data annotation, on the other hand, is broader—it not only labels data but also adds context, relationships, and metadata. In short, labeling answers “what is this?” while annotation answers “what is it, where is it, and how is it connected?”
2. Why are data annotation and labeling critical for AI success?
Without high-quality annotated and labeled data, even the most advanced AI models struggle to perform reliably. These processes ensure that models learn from accurate, structured, and context-rich inputs, directly impacting accuracy, fairness, and explainability.
3. How does quality control work in data annotation and labeling?
Quality is maintained through structured review layers, gold-standard datasets, inter-annotator agreement, and human-in-the-loop workflows. Poor quality at this stage directly reduces model performance and generalization
4. How can businesses choose the right partner for data annotation and labeling?
Organizations should look for providers with domain expertise, human-in-the-loop quality assurance, secure infrastructure, and scalable delivery models. The right partner ensures accuracy, compliance, and speed—while aligning with long-term AI goals.