

Quick Overview
This blog explores the challenges in eCommerce product categorization and how Human-in-the-Loop (HITL) solutions can address them. It highlights how HITL enhances AI-driven categorization by providing human expertise to solve issues like vague descriptions, inconsistent metadata, and evolving taxonomies.
Key points include:
- How HITL improves product categorization by supplementing AI with contextual judgment.
- The role of human reviewers in addressing missing or inconsistent product data.
- HITL excels at keeping pace with rapidly evolving product categories and seasonal trends.
- How HITL supports scalability and ensures consistency in eCommerce categorization.
Introduction:
eCommerce product categorization is the process of organizing products into defined groups such as “Electronics > Mobiles & Accessories > Smartphones & Basic Mobiles > Smartphones”. This helps shoppers easily find what they’re looking for. Product categorization affects search relevance, navigation, recommendation systems, and inventory management.
However, considering the thousands of new SKUs added daily, eCommerce product categorization is no mean feat, especially when a lot of these products have inconsistent or incomplete data.
Automated Machine Learning (ML) solutions are helpful when it comes to speed and scale but frequently fall short due to the nuanced and subjective nature of categorization decisions. That’s where Human-in-the-Loop (HITL) approaches step in, to supplement, validate, and refine what machines alone can’t do.
Let’s take a look at some of the most pressing challenges in eCommerce product categorization and explore how HITL solves them.
Vague, Incomplete, or Inconsistent Product Descriptions
When sellers upload products, they often provide minimal or unclear descriptions. Imagine a listing titled “Stylish Top” with no additional details such as fabric, style, length, or fit.
Why This is a Problem for ML Models
ML models depend heavily on structured, labeled data, including textual and visual features to make categorization decisions. When product titles, descriptions, and images lack detail or use ambiguous language, models produce inaccurate classifications or default to generic categories. Worse, misclassifications may go unnoticed and negatively affect the user experience over time.
How HITL Solves This
Human reviewers can analyze context and make informed judgments when the machine’s confidence is low. Over time, this human feedback helps retrain models, reducing future reliance on manual intervention. Here’s how this works.
- Contextual Understanding: A human can infer that the “Stylish Top” shown in the image is a crop top with puffed sleeves suitable for casual wear—something no generic model can determine with confidence.
- Supplementing Missing Info: Human annotators can augment listings by referencing product images, brand catalogs, or common category norms.
- Flagging for Retraining: Vague entries corrected by humans are fed back into the ML pipeline to improve model learning over time.
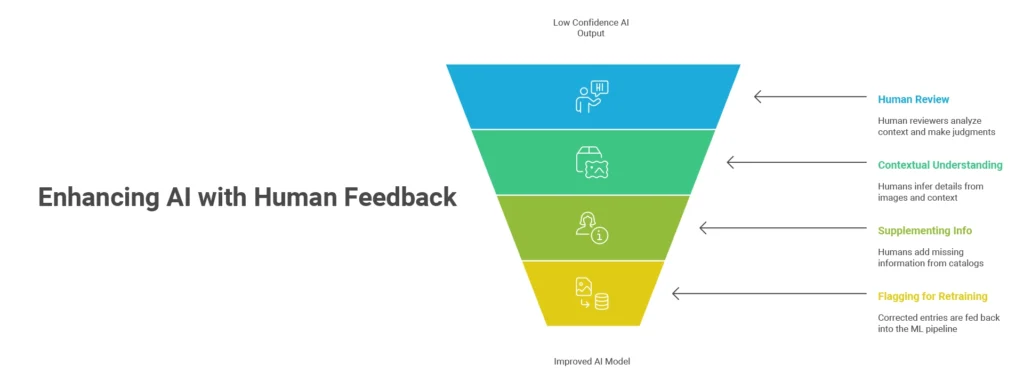
By creating a feedback loop, HITL transforms unclear inputs into usable data and trains the model to recognize similar patterns more accurately in the future.
Inconsistent or Missing Metadata
Metadata such as brand, material, size, color, and technical specs are essential for categorizing products accurately. However, metadata is often inconsistent, misspelled, or altogether missing. For instance, a product might list “Samsng” as the brand or omit the screen size of a television.
Why This is a Problem for ML Models
ML models struggle with irregularities, especially if they’ve been trained on clean, structured datasets. Missing or corrupted metadata leads to false positives, incorrect assumptions, or complete categorization failure.
How HITL Solves This
Humans can validate metadata by spotting errors that an algorithm might overlook, such as subtle spelling mistakes or misleading synonyms. Human evaluators can strengthen metadata using
- Data Normalization: Human agents can identify variations like “blue”, “navy blue”, and “sky blue” and map them to a consistent value that fits the platform’s schema.
- Metadata Imputation: Missing values, such as screen size or material, can be manually filled by referencing product specs or manufacturer sites.
- Validation and Standardization: HITL teams can create and maintain metadata dictionaries to ensure long-term consistency across product lines and sellers.

This human refinement ensures that metadata is not just cleaned but made actionable, enabling ML to learn from corrected records and reducing future inconsistencies.
Ever-Evolving Categories and Taxonomies
eCommerce categories aren’t static. They evolve rapidly due to trends, innovations, and consumer demands. A product that didn’t exist last year, like “neck fans” or “AI-powered desk lamps”, may now need its own category.
Why This is a Problem for ML Models
ML systems trained on old taxonomies struggle to adapt to new structures or product types. A model trained a year ago may not know how to categorize newer products. They might lump new products into broader, less relevant categories, hurting search accuracy and product filtering.
How HITL Solves This
Human experts can intervene to recategorize products and update taxonomies in real time. HITL allows for agile adaptation, ensuring categorization keeps pace with market trends. This can be achieved through
- Early Signal Detection: Human reviewers spot emerging product types earlier than models and flag them for category creation or refinement.
- Taxonomy Re-mapping: Human annotators can suggest merging, splitting, or renaming categories based on shopper behavior, product influx, and search trends.
- Support for Ongoing Evolution: Human feedback guides periodic retraining of ML models, ensuring they adapt to revised taxonomies without breaking logic in existing product classifications.
With HITL, taxonomies are allowed to grow and change without sacrificing categorization accuracy.
Time-Sensitive or Seasonal Categories
Some product categories become popular only during specific times of the year—think “Back to School,” “Diwali Gifts,”, “Christmas Home Decor,” or “Summer Essentials.” These seasonal or event-driven categories are critical for driving conversions during peak periods but often don’t fit neatly into the more regular categories.
Why This is a Problem for ML Models
ML models trained on historical, year-round data often fail to recognize or adapt quickly to temporary categories. They may place a “Diwali light string” under generic “Home Decor > Lighting” instead of the more commercially strategic “Festive Decor.”
How HITL Solves This
Human evaluators are more attuned to seasonal and time-sensitive categories and can thus help with
- Rapid Taxonomy Adjustments: Human reviewers can proactively reclassify products under newly introduced seasonal categories.
- Contextual Interpretation: HITL teams can use cues like product launch timing, promotional language, or marketing metadata to correctly assign temporary but relevant categories.
- Deactivation and Reversion: After the event or season passes, humans can help reclassify products to their default evergreen categories, thus avoiding clutter.
By incorporating HITL, businesses ensure that products surface in the right context at the right time, maximizing visibility and sales during short-lived windows of opportunity.
Multilingual and Regional Variations
A single product can be described in vastly different ways depending on the region. Take the word pants: in the US, it means trousers; in the UK, it refers to underwear. Language and culture deeply influence product descriptions and consumer understanding. Product descriptions in non-English languages further complicate the categorization process.
Why This is a Problem for ML Models
While Natural Language Processing (NLP) models are improving in language translation and interpretation, regional colloquialisms and culture-specific terms can often be confusing. Visual models, too, may misinterpret contextual clues when combined with localized text.
How HITL Solves This
Humans with regional knowledge can bridge the semantic gaps. HITL ensures that product context, both linguistic and cultural, is accurately understood. This human layer brings nuance that AI simply can’t replicate yet, especially when dealing with hyper-local or multilingual product listings. HITL provides crucial local intelligence through
- Language Localization: Human annotators fluent in specific languages ensure accurate interpretation of colloquial or regional terms.
- Cultural Context: Humans can distinguish between functionally similar items that differ in use or meaning across geographies.
- Geo-based Overrides: HITL systems can create rules or exceptions for how a product is categorized based on country-specific taxonomy requirements.
HITL thus ensures that a product is not only categorized correctly, but also meaningfully for each market.
Cross-Category and Multi-Purpose Products
Many modern products don’t always fit neatly into one category. For example, “yoga pants with hidden pockets” could be classified under activewear, loungewear, or even maternity wear depending on the target audience. Similarly, a “smart light with Bluetooth speaker” can blur the line between lighting and electronics and a “smart helmet” might belong to safety gear as well as tech gadgets, thus defying single-category placement conventions.
Why This is a Problem for ML Models
ML models are trained to choose the most likely category, but multi-functional items confuse single-label classification approaches. Even with confidence scores, there’s no guarantee the model picks the most commercially viable category.
How HITL Solves This
Human reviewers can assess a product’s primary use case and assign the most logical category, often after referencing similar products or browsing behavior trends. They can also flag products for multi-category tagging or suggest taxonomy adjustments, adding a flexible and intelligent layer to rigid model logic. Here’s how HITL achieves this kind of layered cross-categorization.
- Primary vs. Secondary Use Case Analysis: Humans can determine which function is more relevant to consumers and choose the dominant category.
- Edge Case Identification: Human reviewers can label items for cross-listing where allowed, ensuring products appear in more than one relevant category.
- Custom Category Suggestions: HITL teams can recommend new compound categories, e.g., “Convertible Furniture”, when trends warrant it.
This human intervention ensures that multi-functional products don’t fall through the cracks of a rigid ML system.
Categorization under Complex Categories
Some verticals, like industrial supplies, automotive parts, or niche collectibles, have intricate and layered category trees. Understanding whether a “rotary hammer” should go under “Construction Tools > Power Tools > Drills > Rotary Hammer Drills” versus a general “Tools > Hammers” category requires specialized knowledge.
Why This is a Problem for ML Models
Without large domain-specific datasets, ML models struggle with such complexity. Small nuances in terminology or design can significantly alter the product’s intended use, which the model may misinterpret without the availability of expert data. Errors here aren’t just inconvenient—they can lead to business losses or safety issues.
How HITL Solves This
Human experts with vertical-specific knowledge ensure precision. For complex categories, HITL reviewers use vendor documentation, part numbers, and visual inspection to assign the correct category. HITL brings much-needed specialized knowledge to the table through
- Subject Matter Experts (SMEs): Domain-specific annotators bring years of product knowledge that machines cannot replicate.
- Technical Validation: Experts can verify product specs, certifications, and intended use before assigning categories.
- Custom Hierarchies: HITL teams can help develop unique taxonomies for B2B or specialized verticals, ensuring the structure is practical and scalable.
In such contexts, HITL is not just helpful; it’s essential.
Visual Similarities and Semantic Differences
Some products look nearly identical but serve different purposes. For example, a weighted blanket and a regular comforter are similar in appearance but completely different in function and target market. Or say, a portable Bluetooth speaker and a smart home assistant, both of which are small, rounded devices with buttons and LEDs, have different uses.
Why ML Models Struggle
Image-based ML models tend to over-index on shape and color. Without deeper semantic understanding or complete metadata, they often lump together functionally distinct items. A visual match isn’t always a purpose match.
How HITL Helps
Human experts can interpret visual and semantic differences better.
- Functional Differentiation: Human reviewers interpret product features in context, for instance, weight, dimensions, or keywords.
- Category Precision: They can discern that a round speaker-shaped device with “Hey Alexa” in the description is not audio equipment, but a smart assistant.
- Improved Model Training: Humans flag edge cases, helping future models learn to distinguish lookalike items based on subtler features.
By resolving these ambiguities, HITL ensures customers find what they’re looking for and not what the algorithm thinks looks similar.
Long-Tail Products
Long-tail products are niche, infrequent, or highly specific items. Think dog wheelchairs for senior pets or those with special needs. Or USB-powered mini aquarium heaters, for example.
Why ML Models Struggle
Long-tail products are statistically underrepresented in training data. They don’t appear often enough for the model to “learn” them confidently, leading to overgeneralization or misclassification into broad, unhelpful categories like “Other” or “Home Essentials.”
How HITL Helps
Human annotators can identify long-tail products and categorize them as needed.
- Manual Tagging for Rarity: Humans can accurately place unique items even when no clear precedent exists in the taxonomy.
- Depth without Noise: They preserve catalog depth by ensuring these rare but valuable listings are not lost or buried.
- New Subcategory Input: HITL teams can recommend permanent category changes when long-tail trends start to gain traction (e.g., pet mobility aids becoming a dedicated subcategory).
The Role of HITL in Ongoing Categorization Workflows
HITL is way more than a contingency plan or a final checkpoint. As product catalogs become more dynamic, diverse, and data-rich, the value of HITL lies in its ability to continuously improve machine learning outputs while keeping human intelligence at the center of decision-making.
Think of HITL as a collaborative learning system, where machines handle volume and speed, while humans provide judgment, context, and domain expertise. As a result, categorization not only becomes accurate but also becomes adaptive, intelligent, and scalable.
By implementing human expertise into categorization workflows, businesses create a self-improving loop.
The ML model makes a prediction > A human validates or corrects it > This feedback is used to retrain the model > Over time, accuracy improves, and the need for manual input decreases.
Let’s explore the common HITL models used in eCommerce categorization, and the specific benefits they bring.
Common HITL Models in Categorization
Pre-labeling + Human Review
In this model, the machine performs the initial categorization. Human reviewers then verify or edit the suggested labels. This is ideal for high-volume environments where model performance is moderately reliable but needs supervision to ensure quality.
Use case example:
An eCommerce platform handling 500,000+ SKUs per month might use pre-labeling to classify basic apparel or electronics. Human reviewers then audit batches, correcting any errors before listings go live.
Benefits:
- Improves speed while maintaining accuracy
- Efficient for large-scale categorization with a moderate margin for error
- Creates rich, validated data for ongoing model retraining
Active Learning
Active learning is a smart, selective approach, where instead of reviewing every prediction, the model flags only low-confidence predictions for human intervention. This ensures human effort is focused only where it’s truly needed.
Use case example:
In a platform selling across multiple regions, products with local terminology or emerging trends may fall into the low-confidence bracket. These are sent to human reviewers while the rest are auto-approved.
Benefits:
- Reduces manual workload significantly
- Prioritizes edge cases, increasing precision in complex scenarios
- Allows models to self-identify knowledge gaps over time
Manual Tagging of Edge Cases
This model involves human intervention by design, specifically for high-risk, high-value, or highly nuanced product categories. Here, humans are not just validators but primary decision-makers.
Use case example:
Luxury items, rare collectibles, or regulatory-sensitive goods, like medical devices or child safety gear, may require dedicated human categorization to ensure compliance, accuracy, and brand trust.
Benefits:
- Ensures top-tier accuracy for high-stakes items
- Captures nuances and exceptions machines often miss
- Builds training data for categories where ML models currently lack expertise
Benefits of HITL Integration
Improves Accuracy Over Time
Every human correction serves as training data that improves the model’s understanding. Over time, the ML system becomes more accurate and confident across a wider variety of products. This is the cycle of continuous learning, where corrections become teaching signals, edge cases are incorporated into future model training, and confidence thresholds become more reliable. In effect, HITL is not just correcting the present, it is also shaping the future performance of the model.
Reduces Manual Overhead
As model confidence grows and accuracy improves, the workload for human teams decreases. HITL enables organizations to scale smarter by shifting human efforts from volume-based review to strategy-based review, including monitoring system performance, addressing anomalies, and training new verticals or taxonomies. This transition reduces cost while increasing operational agility.
Keeps Pace with Change
eCommerce evolves quickly. New products emerge, categories get redefined, and consumer expectations shift with trends. HITL enables rapid adaptation to such changes because human teams can flag when new taxonomies are needed. Annotators catch emerging categories before they impact the consumer experience and localized experts ensure cultural or regional nuances are captured in real-time. Without HITL, ML models run the risk of lagging behind. With it, systems are proactive, not reactive.
Builds Trust and Consistency
When categorization is inconsistent, customers lose trust because they can’t find what they need. They question product quality and eventually abandon carts. HITL enforces a consistency layer by ensuring similar products are placed together, redundant categories are removed, and brand-specific conventions are followed. This is especially critical in marketplaces with third party sellers.
Perfect product categorization is a tall order in the fast-paced, diverse world of eCommerce, but it’s also essential. Poor categorization doesn’t just create friction in the shopping experience, it impacts conversion rates, inventory accuracy, and brand credibility.
Machines offer the scale and speed required to manage massive datasets, while humans bring context, judgment, and cultural sensitivity. The HITL approach bridges the two, offering the best of both worlds.
At NextWealth, we specialize in designing custom HITL workflows for eCommerce platforms of all sizes. From managing multilingual product data to handling high-SKU volume taxonomy projects, we ensure your categorization engine gets smarter with every interaction.
Let our experts help you combine automation with human insight, for categorization that’s not just accurate, but intelligent.