

The Evolution of Online Shopping and Why Product Data Matters More Than Ever
The shift toward online shopping has been both rapid and transformative, with e-commerce growing rapidly after the pandemic. Customers no longer depend on a single channel. They move between marketplaces, brand websites, social platforms, and offline stores while researching products before making a purchase.
Traditional differentiators such as fast delivery, easy returns, and attractive discounts have become baseline expectations. What now influences buying decisions is the quality and completeness of product information. Customers expect clear, consistent, and accurate details that help them compare options and evaluate suitability. Missing attributes, vague descriptions, or inconsistent data across channels create friction and quickly erode trust.
As shopper journeys become more research-driven, enriched product data has become central to the overall experience. It improves product discoverability, supports informed decision-making, and enables meaningful personalization. AI-driven search and recommendation systems rely heavily on structured attributes and high-quality metadata to understand products and match them with user intent.
In a highly competitive digital environment, strong product data is no longer operational hygiene. It is a strategic asset that directly influences engagement, conversions, returns, and long-term loyalty.
Understanding Product Data Enrichment
Product data enrichment refers to the process of transforming basic product information into rich, structured, accurate, and contextually relevant content that improves how shoppers search, evaluate, and engage with products online. In a digital ecosystem where customer decisions depend heavily on product clarity and confidence, enriched data becomes the foundation for superior discovery and personalized shopping experiences.
At its core, product data enrichment enhances the completeness, depth, and usability of product information across all customer touchpoints. A comprehensive product data enrichment process typically includes several interconnected components.
Detailed Descriptions
Creating clear, accurate, and benefit-oriented descriptions that explain features, highlights, use-cases, and value propositions. This helps customers understand how the product fits into their lives and improves engagement.
Technical Specifications
Standardizing key specifications such as dimensions, weight, materials, ingredients, compatibility, and performance metrics. Consistent technical data strengthens product comparison, filtering accuracy, and reduces post-purchase dissatisfaction.
Image and Media Enrichment
Enhancing product visuals with high-resolution images, multiple angles, contextual shots, and zoomable details, 360-degree videos. Supplementing this with videos, tutorials, or demos improves customer confidence and reduces returns.
Customer Reviews and Ratings Integration
Incorporating verified reviews, ratings, and recurring themes from user feedback. This provides social proof, enriches product narratives, and contributes valuable sentiment signals that influence purchasing decisions.
Availability and Fulfillment Details
Adding stock status, delivery timelines, return policies, and fulfillment options. Transparent availability data reduces friction and supports informed purchasing decisions.
Related Products and Recommendations
Linking products based on attributes, compatibility, or customer behavior. This enables cross-sell and upsell journeys through complementary items, alternatives, and popular combinations.
Taxonomy, Categories, and Tags
Accurate product classification supported by deep tagging. This includes style, fabric, use-case, seasonality, model variations, and other contextual attributes that power search and discovery systems.
Core Attributes
Capturing and standardizing foundational attributes such as color, size, pattern, fit, style, capacity, and model. Rich attribute data improves filters, comparison tools, and compatibility matching.
Pricing and Promotional Information
Including base price, offer price, savings breakdown, and competitive price comparisons. Transparent pricing helps customers evaluate value and drives higher conversion.
Brand and Trust Information
Adding brand background, certifications, warranties, sustainability claims, and product guarantees. These trust-building elements influence customer confidence and reduce hesitation.
Usage Instructions and Care Guidelines
Providing how-to-use information, installation steps, maintenance tips, and safety guidance. Clear instructions help reduce returns and customer service queries.
Compliance, Certifications, and Standards
Including allergen information, safety certifications, quality standards, and regulatory compliance details. These are essential for categories such as food, beauty, electronics, and baby products.
SEO and Metadata Optimization
Enhancing titles, URLs, meta descriptions, schema markup, alt text, and channel-specific keywords. Strong metadata improves organic visibility and marketplace ranking.
Data Quality and Consistency Controls
Identifying and fixing missing fields, duplication, outdated information, and cross-channel inconsistencies. Data quality governance ensures reliability and prevents listing rejections.
Behavioral and Contextual Enrichment
Using customer search behavior, browsing patterns, and review sentiment to refine product attributes and content. This supports more effective personalization and dynamic merchandising.
Why Product Data Enrichment Is Essential for E-Commerce Success
Product data enrichment has evolved into a strategic capability that directly influences visibility, conversion, and customer experience. As digital commerce becomes more algorithm-driven and research-heavy, enriched data enables brands to perform with precision across every stage of the buying journey. Hence, Product data enrichment is a technical enabler that strengthens the performance of search engines, recommendation models, and digital merchandising systems.
Optimization of Search and Retrieval Systems
Enriched data improves the quality of indexing and retrieval in search engines. Structured attributes, normalized values, and semantic metadata enhance vector embeddings, reduce query ambiguity, and increase precision in ranking models. This leads to more accurate matches between user queries and product results.
Higher Model Accuracy in Recommendations and Personalization
Recommendation engines depend on attribute-rich product vectors to determine similarity and relevance. Without granular attributes and contextual metadata, collaborative and content-based models produce weak or noisy recommendations. Enrichment strengthens feature engineering, improving both cold-start performance and long-term relevance scoring.
Reduction of Data Noise and Operational Overhead
Unstructured or inconsistent product data introduces noise into downstream systems. Enrichment removes duplication, resolves conflicts, and enforces schema consistency. This reduces error propagation across PIM, search engines, ad platforms, and analytics pipelines, lowering operational cost and improving system reliability.
Improved Conversion Through Expectation Alignment
Technical accuracy in specifications, compatibility details, size standards, ingredient lists, and certifications ensures that customers receive products that match digital representations. This reduces expectation gaps, minimizes returns, and improves long-term customer value.
Stronger Insights and Decision Intelligence
Analytics models perform better when product data is enriched and standardized. Attribute-level insights enable deeper diagnostics across price elasticity, assortment gaps, demand forecasting, and SKU-level profitability. Poorly enriched catalogs limit the analytical resolution required for strategic merchandising decisions.
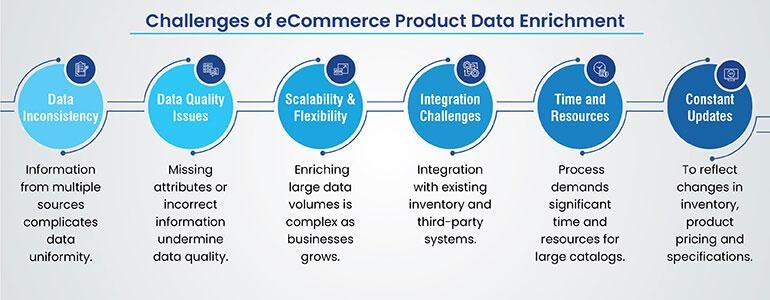
Common Challenges of e-commerce data enrichment
E-commerce product data enrichment is often constrained by fragmented data sources that introduce inconsistency, missing attributes, and quality gaps, making it difficult to maintain a unified and reliable catalog. As product volumes scale, enrichment becomes increasingly complex, especially when integrating enriched data with legacy inventory systems and diverse third-party platforms. The process demands significant time, specialized resources, and continuous maintenance to accommodate evolving product specifications, pricing changes, and channel requirements. These challenges collectively hinder the accuracy, scalability, and operational efficiency of enrichment programs.
Challenges of Automation and the AI + Human-in-the-Loop Hybrid Operating Model for Scalable Enrichment
Purely automated enrichment pipelines offer scale and speed, but they face structural limitations in accuracy, contextual understanding, and compliance. These challenges have led enterprise e-commerce operations to adopt an AI + human-in-the-loop (HITL) hybrid model that balances computational efficiency with human judgment. Below are some of the aspects:
| Area | Challenges with Full Automation |
| Attribute Extraction | Struggles with ambiguous language, multi-meaning descriptors, and incomplete text. Low accuracy when source data is noisy or unstructured (PDFs, labels, images). |
| Classification & Taxonomy Mapping | Misclassifies hybrid or new product types. Weak performance in sparse categories with limited training data. Over-reliance on confidence thresholds. |
| Image & Visual Interpretation | Computer vision models misread colors, patterns, silhouettes under poor lighting or non-standard images. Limited understanding of contextual cues. |
| Semantic Content Generation | Generates inaccurate or hallucinated details without factual grounding. Cannot reliably adapt tone or cultural nuances across regions. |
| Metadata & SEO Optimization | Automated keyword selection may ignore search intent or produce irrelevant keyword stuffing. Cannot judge meaningful vs. superficial SEO terms. |
| Edge Case Handling | Fails silently on out-of-distribution inputs (new products, rare categories). Produces low-confidence or incorrect outputs. |
| Error Detection & Quality Control | Cannot reliably detect logical inconsistencies (e.g., impossible dimensions, contradictory attributes). Requires carefully designed rule engines. |
A scalable and high-precision product data enrichment operation demands more than automation. It requires a hybrid architecture where AI delivers computational speed and pattern recognition, and human experts provide semantic judgment, contextual understanding, and category nuance. This AI + HITL model has become the industry’s most effective approach to building continuously improving enrichment pipelines for large and complex catalogs.
AI as the High-Throughput Engine
AI plays a critical role in processing large volumes of product data quickly. It handles the initial stages of enrichment by ingesting supplier feeds, PDFs, images, unstructured text, and other content types. Through capabilities such as NLP-driven attribute extraction, computer vision for visual attribute detection, multi-label product classification, and automated schema alignment, AI establishes a scalable baseline for enrichment. It can also generate metadata and SEO terms at pace. However, AI alone cannot guarantee semantic precision or compliance accuracy, especially when data is ambiguous or context-sensitive.
Why HITL Is Required Across Every Enrichment Dimension
Human-in-the-Loop involvement fills the gaps that automation inevitably creates. Humans bring the contextual, interpretive, and category-specific understanding that AI is not equipped to apply. This is essential across every enrichment dimension.
Attribute interpretation requires human review when data is unclear or conflicting, ensuring that materials, fit types, compatibility details, and performance characteristics are represented accurately.
Semantic content accuracy demands verification to ensure AI-generated descriptions reflect real product properties, avoid hallucinations, comply with marketplace rules, and maintain the brand’s voice.
Taxonomy and classification benefit from human judgment when products do not neatly fit into predefined categories or when hybrid items confuse algorithms.
Visual data verification is another area where humans excel. Subtle color differences, complex patterns, and style distinctions are consistently misread by computer vision models, and humans ensure these misinterpretations do not enter the final catalog. They also flag images that violate platform policies or misrepresent the product.
Compliance checks are critical in regulated categories such as beauty, electronics, health, and food. AI cannot reliably validate safety warnings, certification claims, allergen disclosures, or voltage requirements.
Multi-channel governance further requires human oversight, as marketplaces differ widely in formatting rules, restricted terms, and image standards.
Finally, logical validation ensures the entire product record is coherent. Humans catch contradictions—like incompatible dimensions, mismatched variants, or conflicting attribute combinations that AI systems cannot reliably detect.
Confidence-Based Routing for Operational Efficiency
To balance accuracy with scalability, hybrid systems use confidence-based routing. AI outputs with high confidence move forward with minimal human intervention. Medium-confidence results are directed to human reviewers for verification. Low-confidence or high-risk outputs, especially in regulated or nuanced categories, are escalated for expert review. This triaged workflow ensures human effort is applied precisely where it is needed, without slowing down the entire process.
Continuous Improvement Through Feedback Loops
One of the strengths of the hybrid model is that it continuously improves. Human corrections are fed back into training datasets, enabling models to learn from real-world errors and edge cases. Over time, this improves attribute extraction, classification accuracy, visual recognition, and the model’s ability to adapt to new product types and evolving taxonomies. The system becomes more accurate and efficient the more it is used.
Multi-Layer Quality Governance
To ensure production-level quality, the hybrid model incorporates multiple layers of validation. Automated rule-based checks and statistical tests catch structural issues early. Semantic and logical reviews ensure accuracy and coherence. Image compliance checks verify that visuals meet marketplace and brand standards. Channel-specific audits ensure every enriched product is ready for deployment across PIM, DAM, CMS, marketplaces, and search engines. This layered governance ensures the final dataset is polished, consistent, and reliable.
NextWealth’s Human-in-the-Loop Advantage for Scalable, High-Quality Product Data Enrichment
At NextWealth, we strengthen AI-driven enrichment pipelines with a trusted Human-in-the-Loop (HITL) layer designed for accuracy, consistency, and scale. As product data becomes more complex and multi-modal, brands rely on us to ensure that AI outputs are validated, corrected, and refined with the human judgment required for real-world e-commerce environments.
Our teams bring deep category expertise across categories and other high-variation segments. This allows us to interpret ambiguous attributes, validate technical specifications, refine AI-generated descriptions, and accurately review visual details, areas where automation alone often struggles. Through disciplined workflows and multi-layer QA, we ensure every enriched product record is complete, coherent, and compliant with marketplace standards.
Beyond enrichment, we support continuous AI improvement by delivering high-quality annotations for model training and validation. This strengthens classification accuracy, attribute extraction performance, and computer vision reliability, enabling our clients’ AI systems to become more effective over time.
With a robust, SLA-driven operations model and flexible capacity, we manage both ongoing catalog programs and surge requirements without compromising quality. We become an extension of our clients’ data operations providing stability, precision, and confidence in every enrichment cycle.
Conclusion
As commerce systems become increasingly algorithm-driven, product data enrichment is no longer just an operational requirement; it is a core input to every machine-learning model that shapes discovery, ranking, and personalisation. The real opportunity ahead lies in treating enrichment as a continuous data engineering pipeline rather than a one-time content exercise. Brands that architect hybrid AI + HITL workflows, invest in feedback loops, and enforce strict data governance will build catalogs that improve autonomously over time. In this next phase of e-commerce, the quality of product data will directly determine the quality of customer experience, and the competitive advantage will belong to those who treat enrichment as an evolving, intelligence-led capability.
Referential Links –
- https://www.fastsimon.com/ecommerce-wiki/optimized-ecommerce-experience/enhancing-online-retail-success-through-product-data-enrichment/
- https://www.catalogix.ai/blog/what-is-e-commerce-product-data-enrichment-and-how-can-your-business-benefit-from-it#:~:text=Product%20data%20enrichment%2C%20also%20known,improving%20their%20overall%20shopping%20experience.
- https://www.mailmodo.com/guides/product-data-enrichment/
- https://www.hitechbpo.com/blog/how-product-data-enrichment-powers-online-catalogs.php